Theoretical Description¶
One method for multi-class calibration has been implemented in MAPIE so far : Top-Label Calibration [1].
The goal of binary calibration is to transform a score (typically given by an ML model) that is not a probability into a probability. The algorithms that are used for calibration can be interpreted as estimators of the confidence level. Hence, they need independent and dependent variables to be fitted.
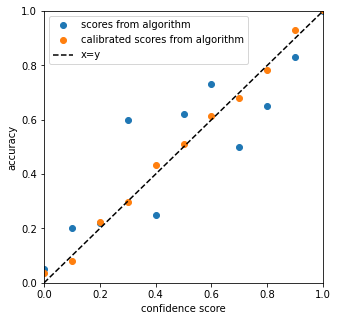
The figure below illustrates what we would expect as a result of a calibration, with the scores predicted being closer to the true probability compared to the original output.
Firstly, we introduce binary calibration, we denote the 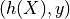 pair as the score and ground truth for the object. Hence,
pair as the score and ground truth for the object. Hence, 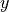 values are in
values are in  . The model is calibrated if for every output
. The model is calibrated if for every output ![q \in [0, 1]](_images/math/50aa5f671af9ac82c4f3b0cbd2c9ceece1a3c438.png) , we have:
, we have:
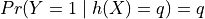
where 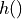 is the score predictor.
is the score predictor.
To apply calibration directly to a multi-class context, Gupta et al. propose a framework, multiclass-to-binary, in order to reduce a multi-class calibration to multiple binary calibrations (M2B).
1. Top-Label¶
Top-Label calibration is a calibration technique introduced by Gupta et al. to calibrate the model according to the highest score and the corresponding class (see [1] Section 2). This framework offers to apply binary calibration techniques to multi-class calibration.
More intuitively, top-label calibration simply performs a binary calibration (such as Platt scaling or isotonic regression) on the highest score and the corresponding class, whereas confidence calibration only calibrates on the highest score (see [1] Section 2).
Let  be the classifier and
be the classifier and 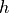 be the maximum score from the classifier. The couple
be the maximum score from the classifier. The couple 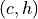 is calibrated
according to Top-Label calibration if:
is calibrated
according to Top-Label calibration if:
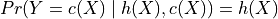
2. Metrics for calibration¶
Expected calibration error
The main metric to check if the calibration is correct is the Expected Calibration Error (ECE). It is based on two
components, accuracy and confidence per bin. The number of bins is a hyperparamater 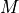 , and we refer to a specific bin by
, and we refer to a specific bin by
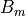 .
.
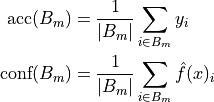
The ECE is the combination of these two metrics combined.
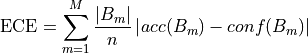
In simple terms, once all the different bins from the confidence scores have been created, we check the mean accuracy of each bin. The absolute mean difference between the two is the ECE. Hence, the lower the ECE, the better the calibration was performed.
Top-Label ECE
In the top-label calibration, we only calculate the ECE for the top-label class. Hence, per top-label class, we condition the calculation of the accuracy and confidence based on the top label and take the average ECE for each top-label.
3. Statistical tests for calibration¶
Kolmogorov-Smirnov test
Kolmogorov-Smirnov test was derived in [2, 3, 4]. The idea is to consider the cumulative differences between sorted scores 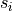 and their corresponding labels
and their corresponding labels 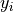 and to compare its properties to that of a standard Brownian motion. Let us consider the
cumulative differences on sorted scores:
and to compare its properties to that of a standard Brownian motion. Let us consider the
cumulative differences on sorted scores:
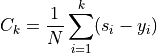
We also introduce a typical normalization scale 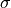 :
:

The Kolmogorov-Smirnov statistic is then defined as :
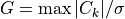
It can be shown [2] that, under the null hypothesis of well-calibrated scores, this quantity asymptotically (i.e. when N goes to infinity)
converges to the maximum absolute value of a standard Brownian motion over the unit interval ![[0, 1]](_images/math/8027137b3073a7f5ca4e45ba2d030dcff154eca4.png) . [3, 4] also provide closed-form
formulas for the cumulative distribution function (CDF) of the maximum absolute value of such a standard Brownian motion.
So we state the p-value associated to the statistical test of well calibration as:
. [3, 4] also provide closed-form
formulas for the cumulative distribution function (CDF) of the maximum absolute value of such a standard Brownian motion.
So we state the p-value associated to the statistical test of well calibration as:
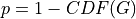
Kuiper test
Kuiper test was derived in [2, 3, 4] and is very similar to Kolmogorov-Smirnov. This time, the statistic is defined as:
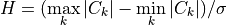
It can be shown [2] that, under the null hypothesis of well-calibrated scores, this quantity asymptotically (i.e. when N goes to infinity)
converges to the range of a standard Brownian motion over the unit interval . [3, 4] also provide closed-form
formulas for the cumulative distribution function (CDF) of the range of such a standard Brownian motion.
So we state the p-value associated to the statistical test of well calibration as:
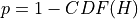
Spiegelhalter test
Spiegelhalter test was derived in [6]. It is based on a decomposition of the Brier score:
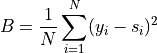
where scores are denoted and their corresponding labels . This can be decomposed in two terms:
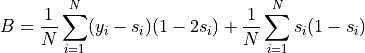
It can be shown that the first term has an expected value of zero under the null hypothesis of well calibration. So we interpret
the second term as the Brier score expected value 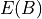 under the null hypothesis. As for the variance of the Brier score, it can be
computed as:
under the null hypothesis. As for the variance of the Brier score, it can be
computed as:
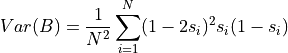
So we can build a Z-score as follows:
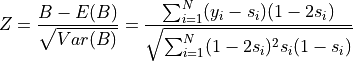
This statistic follows a normal distribution of cumulative distribution CDF so that we state the associated p-value:
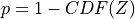
3. References¶
[1] Gupta, Chirag, and Aaditya K. Ramdas. “Top-label calibration and multiclass-to-binary reductions.” arXiv preprint arXiv:2107.08353 (2021).
[2] Arrieta-Ibarra I, Gujral P, Tannen J, Tygert M, Xu C. Metrics of calibration for probabilistic predictions. The Journal of Machine Learning Research. 2022 Jan 1;23(1):15886-940.
[3] Tygert M. Calibration of P-values for calibration and for deviation of a subpopulation from the full population. arXiv preprint arXiv:2202.00100. 2022 Jan 31.
[4] D. A. Darling. A. J. F. Siegert. The First Passage Problem for a Continuous Markov Process. Ann. Math. Statist. 24 (4) 624 - 639, December, 1953.
[5] William Feller. The Asymptotic Distribution of the Range of Sums of Independent Random Variables. Ann. Math. Statist. 22 (3) 427 - 432 September, 1951.
[6] Spiegelhalter DJ. Probabilistic prediction in patient management and clinical trials. Statistics in medicine. 1986 Sep;5(5):421-33.