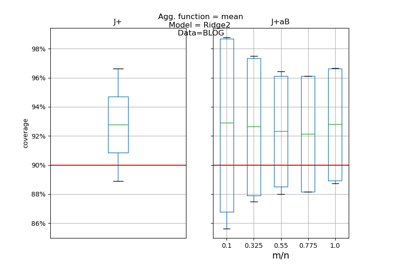
mapie.regression.MapieRegressor¶
- class mapie.regression.MapieRegressor(estimator: Optional[sklearn.base.RegressorMixin] = None, method: str = 'plus', cv: Optional[Union[int, str, sklearn.model_selection._split.BaseCrossValidator]] = None, test_size: Optional[Union[int, float]] = None, n_jobs: Optional[int] = None, agg_function: Optional[str] = 'mean', verbose: int = 0, conformity_score: Optional[mapie.conformity_scores.conformity_scores.ConformityScore] = None, random_state: Optional[Union[int, numpy.random.mtrand.RandomState]] = None)[source]¶
Prediction interval with out-of-fold conformity scores.
This class implements the jackknife+ strategy and its variations for estimating prediction intervals on single-output data. The idea is to evaluate out-of-fold conformity scores (signed residuals, absolute residuals, residuals normalized by the predicted mean…) on hold-out validation sets and to deduce valid confidence intervals with strong theoretical guarantees.
- Parameters
- estimator: Optional[RegressorMixin]
Any regressor with scikit-learn API (i.e. with
fitandpredictmethods). IfNone, estimator defaults to aLinearRegressioninstance.By default
None.- method: str
Method to choose for prediction interval estimates. Choose among:
"naive", based on training set conformity scores,"base", based on validation sets conformity scores,"plus", based on validation conformity scores and testing predictions,"minmax", based on validation conformity scores and testing predictions (min/max among cross-validation clones).
By default
"plus".- cv: Optional[Union[int, str, BaseCrossValidator]]
The cross-validation strategy for computing conformity scores. It directly drives the distinction between jackknife and cv variants. Choose among:
None, to use the default 5-fold cross-validationinteger, to specify the number of folds. If equal to
-1, equivalent tosklearn.model_selection.LeaveOneOut().CV splitter: any
sklearn.model_selection.BaseCrossValidatorMain variants are:sklearn.model_selection.LeaveOneOut(jackknife),sklearn.model_selection.KFold(cross-validation),subsample.Subsampleobject (bootstrap).
"split", does not involve cross-validation but a division of the data into training and calibration subsets. The splitter used is the following:sklearn.model_selection.ShuffleSplit.methodparameter is set to"base"."prefit", assumes thatestimatorhas been fitted already, and themethodparameter is set to"base". All data provided in thefitmethod is then used for computing conformity scores only. At prediction time, quantiles of these conformity scores are used to provide a prediction interval with fixed width. The user has to take care manually that data for model fitting and conformity scores estimate are disjoint.
By default
None.- test_size: Optional[Union[int, float]]
If
float, should be between0.0and1.0and represent the proportion of the dataset to include in the test split. Ifint, represents the absolute number of test samples. IfNone, it will be set to0.1.If cv is not
"split",test_sizeis ignored.By default
None.- n_jobs: Optional[int]
Number of jobs for parallel processing using joblib via the “locky” backend. If
-1all CPUs are used. If1is given, no parallel computing code is used at all, which is useful for debugging. Forn_jobsbelow-1,(n_cpus + 1 - n_jobs)are used.Noneis a marker for unset that will be interpreted asn_jobs=1(sequential execution).By default
None.- agg_function: Optional[str]
Determines how to aggregate predictions from perturbed models, both at training and prediction time.
If
None, it is ignored except ifcvclass isSubsample, in which case an error is raised. If"mean"or"median", returns the mean or median of the predictions computed from the out-of-folds models. Note: if you plan to set theensembleargument toTruein thepredictmethod, you have to specify an aggregation function. Otherwise an error would be raised.The Jackknife+ interval can be interpreted as an interval around the median prediction, and is guaranteed to lie inside the interval, unlike the single estimator predictions.
When the cross-validation strategy is
Subsample(i.e. for the Jackknife+-after-Bootstrap method), this function is also used to aggregate the training set in-sample predictions.If
cvis"prefit"or"split",agg_functionis ignored.By default
"mean".- verbose: int
The verbosity level, used with joblib for multiprocessing. The frequency of the messages increases with the verbosity level. If it more than
10, all iterations are reported. Above50, the output is sent to stdout.By default
0.- conformity_score: Optional[ConformityScore]
ConformityScore instance. It defines the link between the observed values, the predicted ones and the conformity scores. For instance, the default
Nonevalue correspondonds to a conformity score which assumes y_obs = y_pred + conformity_score.None, to use the defaultAbsoluteConformityScoreconformity scoreConformityScore: any
ConformityScoreclass
By default
None.- random_state: Optional[Union[int, RandomState]]
Pseudo random number generator state used for random sampling. Pass an int for reproducible output across multiple function calls.
By default
None.
References
Rina Foygel Barber, Emmanuel J. Candès, Aaditya Ramdas, and Ryan J. Tibshirani. “Predictive inference with the jackknife+.” Ann. Statist., 49(1):486-507, February 2021.
Byol Kim, Chen Xu, and Rina Foygel Barber. “Predictive Inference Is Free with the Jackknife+-after-Bootstrap.” 34th Conference on Neural Information Processing Systems (NeurIPS 2020).
Examples
>>> import numpy as np >>> from mapie.regression import MapieRegressor >>> from sklearn.linear_model import LinearRegression >>> X_toy = np.array([[0], [1], [2], [3], [4], [5]]) >>> y_toy = np.array([5, 7.5, 9.5, 10.5, 12.5, 15]) >>> clf = LinearRegression().fit(X_toy, y_toy) >>> mapie_reg = MapieRegressor(estimator=clf, cv="prefit") >>> mapie_reg = mapie_reg.fit(X_toy, y_toy) >>> y_pred, y_pis = mapie_reg.predict(X_toy, alpha=0.5) >>> print(y_pis[:, :, 0]) [[ 4.95714286 5.61428571] [ 6.84285714 7.5 ] [ 8.72857143 9.38571429] [10.61428571 11.27142857] [12.5 13.15714286] [14.38571429 15.04285714]] >>> print(y_pred) [ 5.28571429 7.17142857 9.05714286 10.94285714 12.82857143 14.71428571]
- Attributes
- valid_methods_: List[str]
List of all valid methods.
- estimator_: EnsembleRegressor
Sklearn estimator that handle all that is related to the estimator.
- conformity_scores_: ArrayLike of shape (n_samples_train,)
Conformity scores between
y_trainandy_pred.- n_features_in_: int
Number of features passed to the
fitmethod.
- __init__(estimator: Optional[sklearn.base.RegressorMixin] = None, method: str = 'plus', cv: Optional[Union[int, str, sklearn.model_selection._split.BaseCrossValidator]] = None, test_size: Optional[Union[int, float]] = None, n_jobs: Optional[int] = None, agg_function: Optional[str] = 'mean', verbose: int = 0, conformity_score: Optional[mapie.conformity_scores.conformity_scores.ConformityScore] = None, random_state: Optional[Union[int, numpy.random.mtrand.RandomState]] = None) None[source]¶
- fit(X: Union[numpy._typing._array_like._SupportsArray[numpy.dtype[Any]], numpy._typing._nested_sequence._NestedSequence[numpy._typing._array_like._SupportsArray[numpy.dtype[Any]]], bool, int, float, complex, str, bytes, numpy._typing._nested_sequence._NestedSequence[Union[bool, int, float, complex, str, bytes]]], y: Union[numpy._typing._array_like._SupportsArray[numpy.dtype[Any]], numpy._typing._nested_sequence._NestedSequence[numpy._typing._array_like._SupportsArray[numpy.dtype[Any]]], bool, int, float, complex, str, bytes, numpy._typing._nested_sequence._NestedSequence[Union[bool, int, float, complex, str, bytes]]], sample_weight: Optional[Union[numpy._typing._array_like._SupportsArray[numpy.dtype[Any]], numpy._typing._nested_sequence._NestedSequence[numpy._typing._array_like._SupportsArray[numpy.dtype[Any]]], bool, int, float, complex, str, bytes, numpy._typing._nested_sequence._NestedSequence[Union[bool, int, float, complex, str, bytes]]]] = None) mapie.regression.regression.MapieRegressor[source]¶
Fit estimator and compute conformity scores used for prediction intervals.
All the types of estimator (single or cross validated ones) are encapsulated under EnsembleRegressor.
- Parameters
- X: ArrayLike of shape (n_samples, n_features)
Training data.
- y: ArrayLike of shape (n_samples,)
Training labels.
- sample_weight: Optional[ArrayLike] of shape (n_samples,)
Sample weights for fitting the out-of-fold models. If
None, then samples are equally weighted. If some weights are null, their corresponding observations are removed before the fitting process and hence have no conformity scores. If weights are non-uniform, conformity scores are still uniformly weighted.By default
None.
- Returns
- MapieRegressor
The model itself.
- predict(X: Union[numpy._typing._array_like._SupportsArray[numpy.dtype[Any]], numpy._typing._nested_sequence._NestedSequence[numpy._typing._array_like._SupportsArray[numpy.dtype[Any]]], bool, int, float, complex, str, bytes, numpy._typing._nested_sequence._NestedSequence[Union[bool, int, float, complex, str, bytes]]], ensemble: bool = False, alpha: Optional[Union[float, Iterable[float]]] = None, optimize_beta: bool = False, allow_infinite_bounds: bool = False) Union[numpy.ndarray[Any, numpy.dtype[numpy._typing._array_like._ScalarType_co]], Tuple[numpy.ndarray[Any, numpy.dtype[numpy._typing._array_like._ScalarType_co]], numpy.ndarray[Any, numpy.dtype[numpy._typing._array_like._ScalarType_co]]]][source]¶
Predict target on new samples with confidence intervals. Conformity scores from the training set and predictions from the model clones are central to the computation. Prediction Intervals for a given
alphaare deduced from eitherquantiles of conformity scores (
naiveandbasemethods),quantiles of (predictions +/- conformity scores) (
plusmethod),quantiles of (max/min(predictions) +/- conformity scores) (
minmaxmethod).
- Parameters
- X: ArrayLike of shape (n_samples, n_features)
Test data.
- ensemble: bool
Boolean determining whether the predictions are ensembled or not. If
False, predictions are those of the model trained on the whole training set. IfTrue, predictions from perturbed models are aggregated by the aggregation function specified in theagg_functionattribute.If
cvis"prefit"or"split",ensembleis ignored.By default
False.- alpha: Optional[Union[float, Iterable[float]]]
Can be a float, a list of floats, or a
ArrayLikeof floats. Between0and1, represents the uncertainty of the confidence interval. Loweralphaproduce larger (more conservative) prediction intervals.alphais the complement of the target coverage level.By default
None.- optimize_beta: bool
Whether to optimize the PIs’ width or not.
By default
False.- allow_infinite_bounds: bool
Allow infinite prediction intervals to be produced.
- Returns
- Union[NDArray, Tuple[NDArray, NDArray]]
NDArray of shape (n_samples,) if
alphaisNone.Tuple[NDArray, NDArray] of shapes (n_samples,) and (n_samples, 2, n_alpha) if
alphais notNone.[:, 0, :]: Lower bound of the prediction interval.
[:, 1, :]: Upper bound of the prediction interval.
- set_fit_request(*, sample_weight: Union[bool, None, str] = '$UNCHANGED$') mapie.regression.regression.MapieRegressor¶
Request metadata passed to the
fitmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
pipeline.Pipeline. Otherwise it has no effect.- Parameters
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
- Returns
- selfobject
The updated object.
- set_predict_request(*, allow_infinite_bounds: Union[bool, None, str] = '$UNCHANGED$', alpha: Union[bool, None, str] = '$UNCHANGED$', ensemble: Union[bool, None, str] = '$UNCHANGED$', optimize_beta: Union[bool, None, str] = '$UNCHANGED$') mapie.regression.regression.MapieRegressor¶
Request metadata passed to the
predictmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredictif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
pipeline.Pipeline. Otherwise it has no effect.- Parameters
- allow_infinite_boundsstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
allow_infinite_boundsparameter inpredict.- alphastr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
alphaparameter inpredict.- ensemblestr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
ensembleparameter inpredict.- optimize_betastr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
optimize_betaparameter inpredict.
- Returns
- selfobject
The updated object.
- set_score_request(*, sample_weight: Union[bool, None, str] = '$UNCHANGED$') mapie.regression.regression.MapieRegressor¶
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
pipeline.Pipeline. Otherwise it has no effect.- Parameters
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns
- selfobject
The updated object.