Getting started with risk control in MAPIE¶
Table of contents
Overview¶
This section provides an overview of risk control in MAPIE. For those unfamiliar with the concept of risk control, the next section provides an introduction to the topic.
Three methods of risk control have been implemented in MAPIE so far : Risk-Controlling Prediction Sets (RCPS) [1], Conformal Risk Control (CRC) [2] and Learn Then Test (LTT) [3].
As of now, MAPIE supports risk control for two machine learning tasks: binary classification, as well as multi-label classification (in particular applications like image segmentation). The table below details the available methods for each task:
Risk control |
Type of |
Assumption |
Non-monotonic |
Binary |
Multi-label |
|---|---|---|---|---|---|
RCPS |
Probability |
i.i.d. |
❌ |
❌ |
✅ |
CRC |
Expectation |
Exchangeable |
❌ |
❌ |
✅ |
LTT |
Probability |
i.i.d |
✅ |
✅ |
✅ |
In MAPIE for multi-label classification, CRC and RCPS are used for recall control, while LTT is used for precision control.
1. What is risk control?¶
Before diving into risk control, let’s take the simple example of a binary classification model, which separates the incoming data into two classes. Predicted probabilities above a given threshold (e.g., 0.5) correspond to predicting the “positive” class and probabilities below correspond to the “negative” class. Suppose we want to find a threshold that guarantees that our model achieves a certain level of precision. A naive, yet straightforward approach to do this is to evaluate how precision varies with different threshold values on a validation dataset. By plotting this relationship (see plot below), we can identify the range of thresholds that meet our desired precision requirement (green zone on the graph).
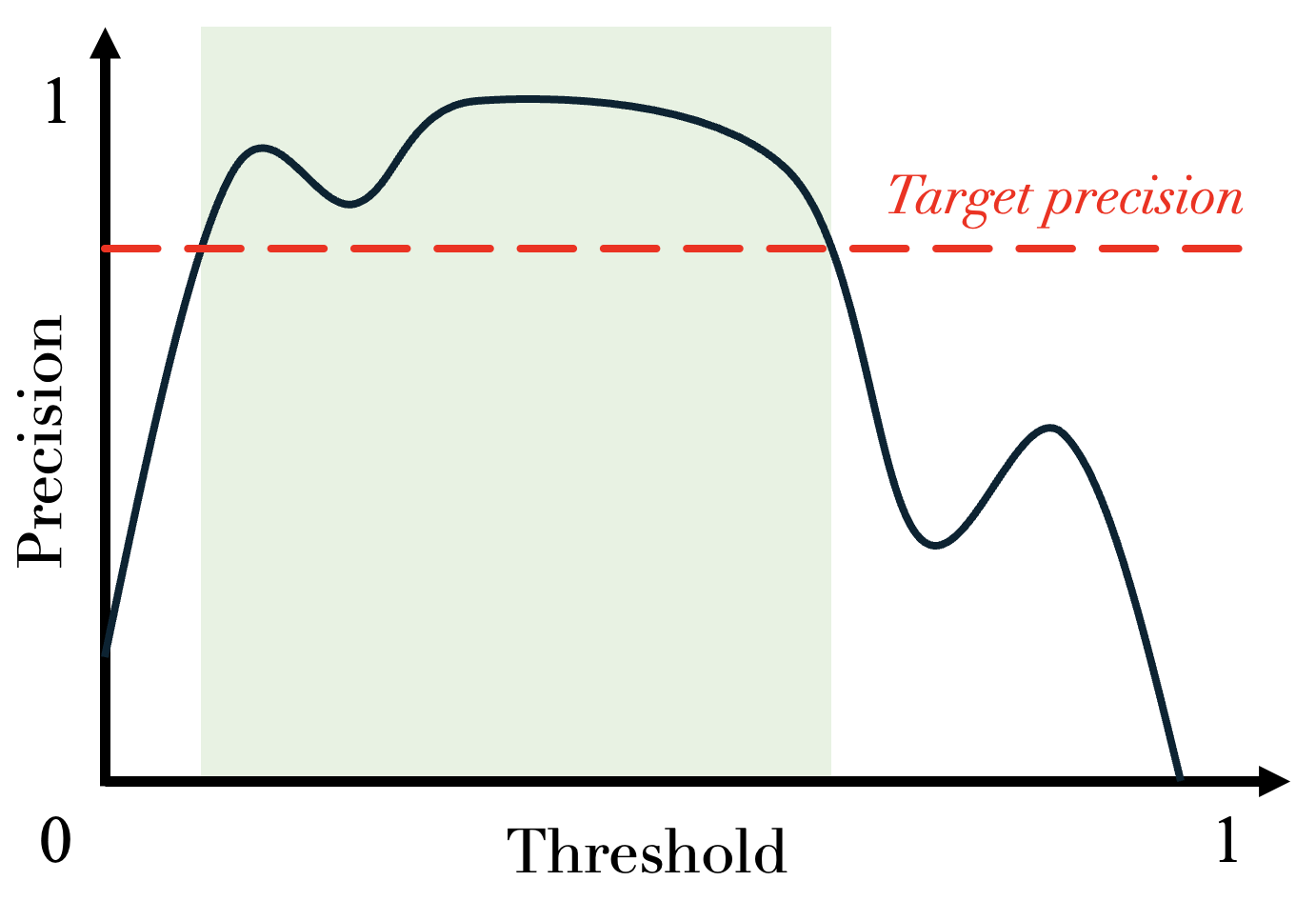
So far, so good. But here is the catch: while the chosen threshold effectively keeps precision above the desired level on the validation data, it offers no guarantee on the precision of the model when faced with new, unseen data. That is where risk control comes into play.
—
Risk control is the science of adjusting a model’s parameter, typically denoted 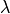 , so that a given risk stays below a desired level with high probability on unseen data.
Note that here, the term risk is used to describe an undesirable outcome of the model (e.g., type I error): therefore, it is a value we want to minimize, and in our case, keep under a certain level. Also note that risk control can easily be applied to metrics we want to maximize (e.g., precision), simply by controlling the complement (e.g., 1-precision).
, so that a given risk stays below a desired level with high probability on unseen data.
Note that here, the term risk is used to describe an undesirable outcome of the model (e.g., type I error): therefore, it is a value we want to minimize, and in our case, keep under a certain level. Also note that risk control can easily be applied to metrics we want to maximize (e.g., precision), simply by controlling the complement (e.g., 1-precision).
The strength of risk control lies in the statistical guarantees it provides on unseen data. Unlike the naive method presented earlier, it determines a value of that ensures the risk is controlled beyond the validation data.
Applying risk control to the previous example would allow us to get a new — albeit narrower — range of thresholds (blue zone on the graph) that are statistically guaranteed.
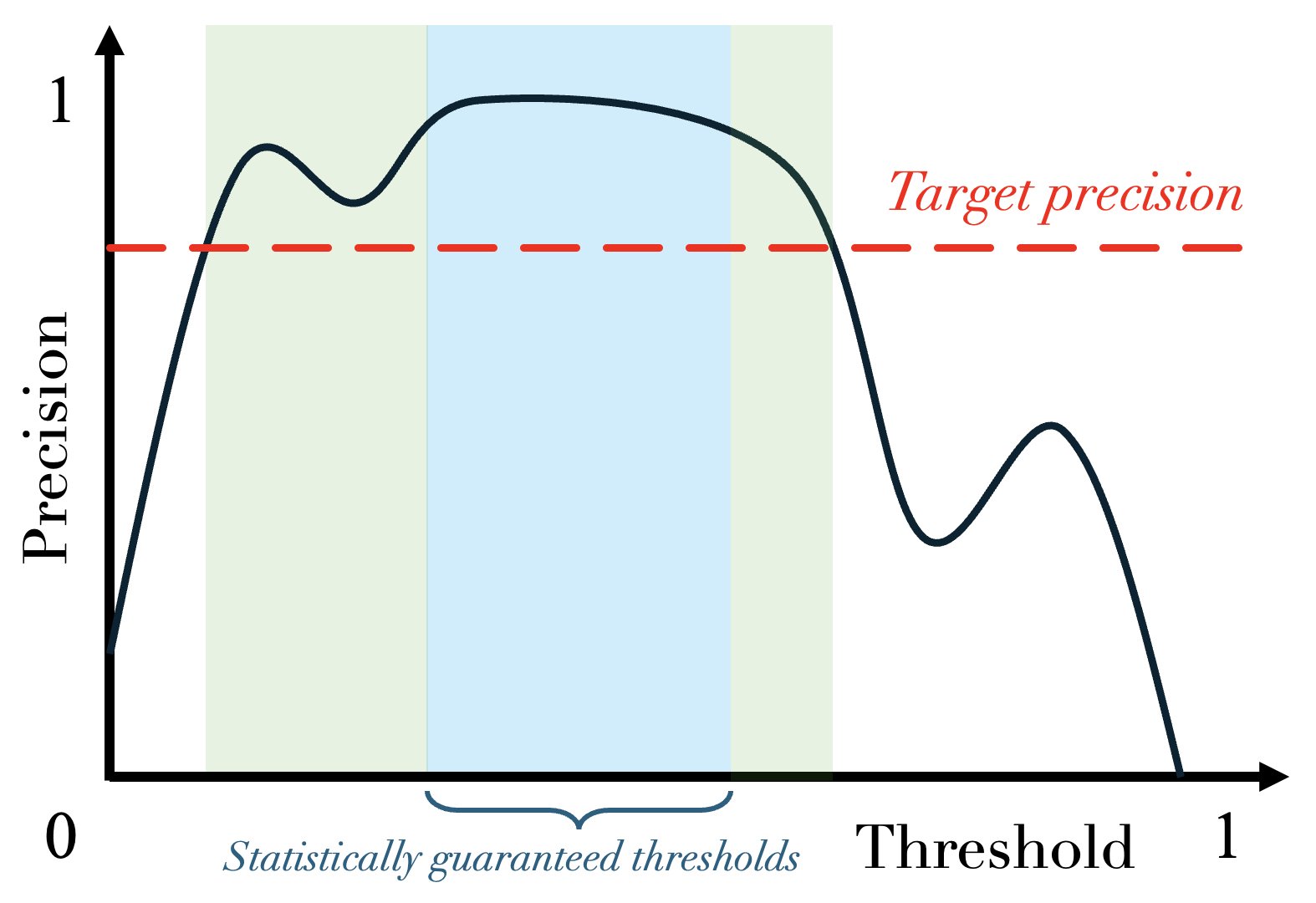
This guarantee is critical in a wide range of use cases (especially in high-stakes applications), and can be applied to any risk or metric: in the example above, it was the precision that was controlled, but the same can be done with the recall, for example. Take medical diagnosis: here, the parameter is the binarization threshold that determines whether a patient is classified as sick. We aim to minimize false negatives (i.e., cases where sick patients are incorrectly diagnosed as healthy), which corresponds to controlling the recall. In this setting, risk control allows us to find a such that, on future patients, the model’s recall remains above, say, 95%, with high confidence.
—
To express risk control in mathematical terms, we denote by 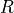 the risk we want to control, and introduce the following two parameters:
the risk we want to control, and introduce the following two parameters:
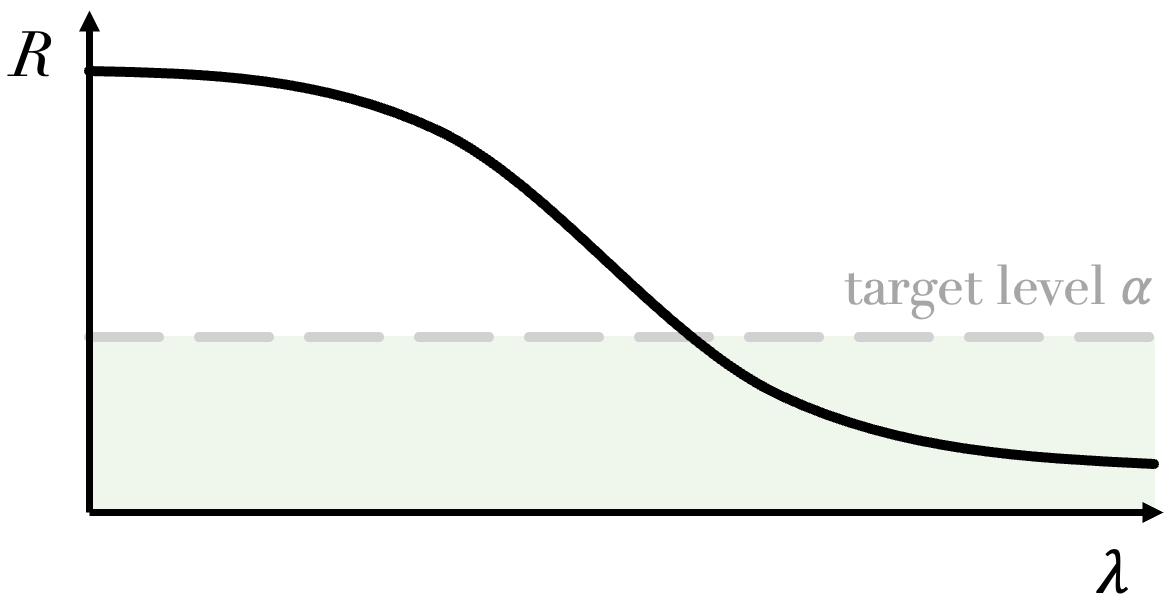
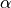 : the target level below which we want the risk to remain, as shown in the figure below;
: the target level below which we want the risk to remain, as shown in the figure below;
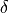 : the confidence level associated with the risk control.
: the confidence level associated with the risk control.
In other words, the risk is said to be controlled if 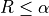 with probability at least
with probability at least 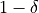 , where the probability is over the randomness in the sampling of the dataset.
, where the probability is over the randomness in the sampling of the dataset.
The three risk control methods implemented in MAPIE — RCPS, CRC and LTT — rely on different assumptions, and offer slightly different guarantees:
CRC requires the data to be exchangeable, and gives a guarantee on the expectation of the risk:
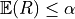 ;
;RCPS and LTT both impose stricter assumptions, requiring the data to be independent and identically distributed (i.i.d.), which implies exchangeability. The guarantee they provide is on the probability that the risk does not exceed
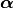 :
: 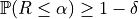 .
.
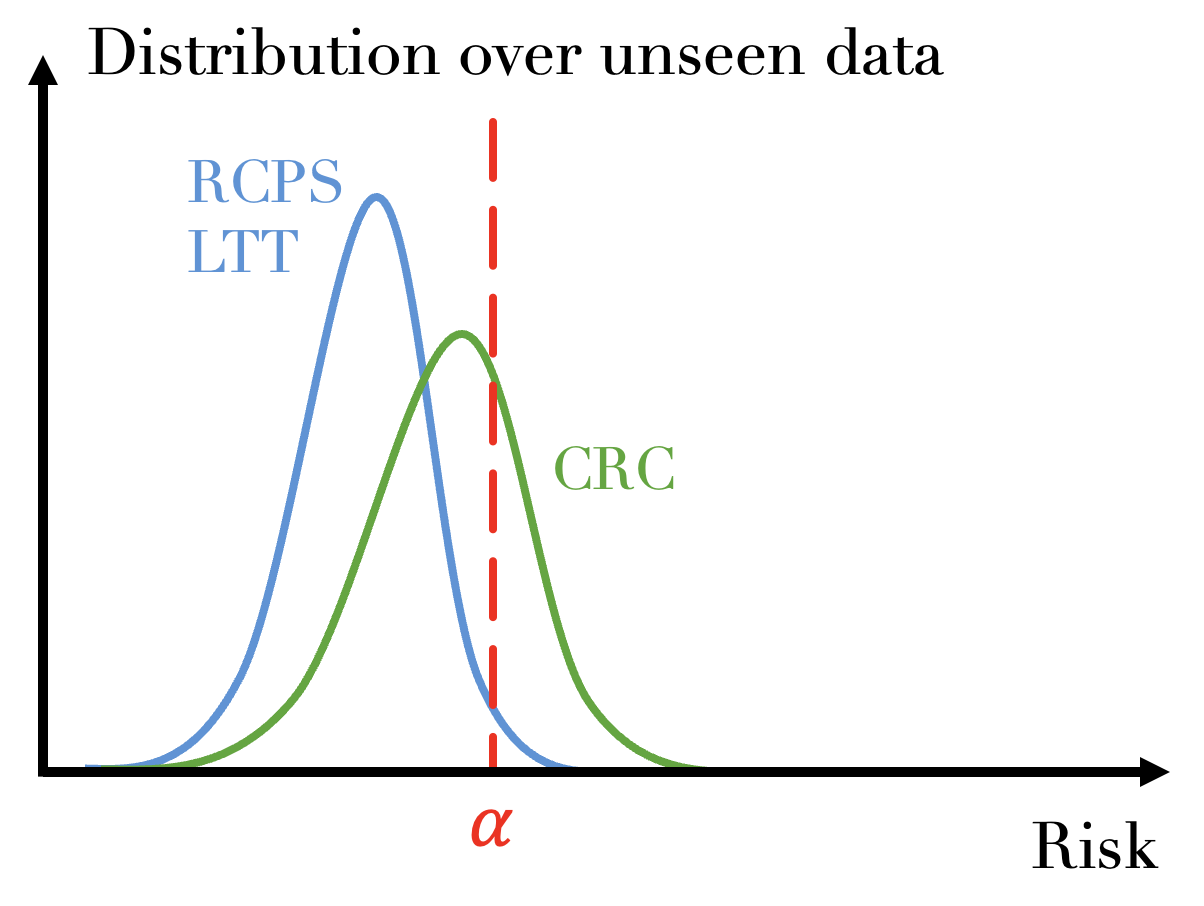
The plot above gives a visual representation of the difference between the two types of guarantees:
The risk is controlled in expectation (CRC) if the mean of its distribution over unseen data is below
;The risk is controlled in probability (RCPS/LTT) if at least
percent of its distribution over unseen data is below .
Note that contrary to the other two methods, LTT allows to control any non-monotonic risk.
The following section provides a detailed overview of each method.
2. Theoretical description¶
2.1 Risk-Controlling Prediction Sets¶
2.1.1 General settings¶
Let’s first give the settings and the notations of the method:
Let
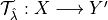 be a set-valued function (a tolerance region) that maps a feature vector to a set-valued prediction. This function is built from the model which was previously fitted on the training data. It is indexed by a one-dimensional parameter which is taking values in
be a set-valued function (a tolerance region) that maps a feature vector to a set-valued prediction. This function is built from the model which was previously fitted on the training data. It is indexed by a one-dimensional parameter which is taking values in 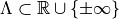 such that:
such that:
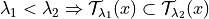
Let
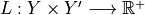 be a loss function on a prediction set with the following nesting property:
be a loss function on a prediction set with the following nesting property:
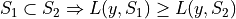
Let
be the risk associated to a set-valued predictor:
![R(\mathcal{T}_{\hat{\lambda}}) = \mathbb{E}[L(Y, \mathcal{T}_{\lambda}(X))]](_images/math/a32b90487aaaaa378071172fe9f890a8143c3df7.png)
The goal of the method is to compute an Upper Confidence Bound (UCB) 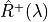 of
of 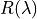 and then to find
and then to find
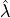 as follows:
as follows:
The figure below explains this procedure:
Following those settings, the RCPS method gives the following guarantee on the recall:
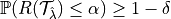
2.1.2 Bounds calculation¶
In this section, we will consider only bounded losses (as for now, only the 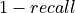 loss is implemented).
We will show three different Upper Calibration Bounds (UCB) (Hoeffding, Bernstein, and Waudby-Smith–Ramdas) of
based on the empirical risk which is defined as follows:
loss is implemented).
We will show three different Upper Calibration Bounds (UCB) (Hoeffding, Bernstein, and Waudby-Smith–Ramdas) of
based on the empirical risk which is defined as follows:
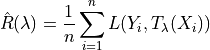
2.1.2.1 Hoeffding Bound¶
Suppose the loss is bounded above by one, then we have by the Hoeffding inequality that:
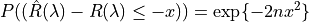
Which implies the following UCB:
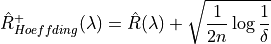
2.1.2.2 Bernstein Bound¶
Contrary to the Hoeffding bound, which can sometimes be too simple, the Bernstein UCB takes into account the variance and gives a smaller prediction set size:
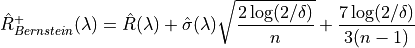
Where:
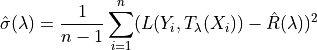
2.1.2.3 Waudby-Smith–Ramdas¶
This last UCB is the one recommended by the authors of [1] to use when using a bounded loss as this is the one that gives the smallest prediction sets size while having the same risk guarantees. This UCB is defined as follows:
Let 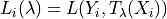 and
and
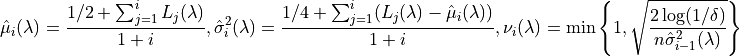
Further let:
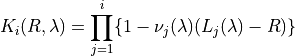
Then:
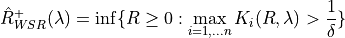
2.2 Conformal Risk Control¶
The goal of this method is to control any monotone and bounded loss. The result of this method can be expressed as follows:
![\mathbb{E}\left[L_{n+1}(\hat{\lambda})\right] \leq \alpha](_images/math/6bcc896c150a266188cd4463e6b87ed4d22b308a.png)
Where 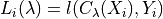
In the case of multi-label classification, 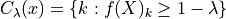
To find the optimal value of , the following algorithm is applied:
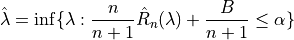
With :
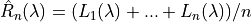
2.3 Learn Then Test¶
We are going to present the Learn Then Test framework that allows the user to control non-monotonic risk such as precision score. This method has been introduced in article [3]. The settings here are the same as RCPS and CRC, we just need to introduce some new parameters:
Let
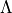 be a discretized set for our , meaning that
be a discretized set for our , meaning that 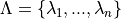 .
.Let
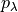 be a valid p-value for the null hypothesis
be a valid p-value for the null hypothesis 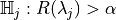 .
.
The goal of this method is to control any loss whether monotonic, bounded, or not, by performing risk control through multiple hypothesis testing. We can express the goal of the procedure as follows:
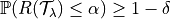
In order to find all the parameters that satisfy the above condition, the Learn Then Test framework proposes to do the following:
First across the collections of functions
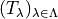 , we estimate the risk on the calibration data
, we estimate the risk on the calibration data
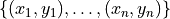 .
.For each
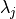 in a discrete set
in a discrete set 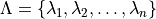 , we associate the null hypothesis
, we associate the null hypothesis
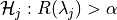 , as rejecting the hypothesis corresponds to selecting as a point where the risk
is controlled.
, as rejecting the hypothesis corresponds to selecting as a point where the risk
is controlled.For each null hypothesis, we compute a valid p-value using a concentration inequality
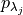 . Here we choose to compute the Hoeffding-Bentkus p-value
introduced in the paper [3].
. Here we choose to compute the Hoeffding-Bentkus p-value
introduced in the paper [3].Return
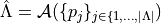 , where
, where 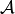 , is an algorithm
that controls the family-wise error rate (FWER), for example, Bonferonni correction.
, is an algorithm
that controls the family-wise error rate (FWER), for example, Bonferonni correction.
Note that a notebook testing theoretical guarantees of risk control in binary classification using a random classifier and synthetic data is available here: theoretical_validity_tests.ipynb.
References¶
[1] Lihua Lei Jitendra Malik Stephen Bates, Anastasios Angelopoulos, and Michael I. Jordan. Distribution-free, risk-controlling prediction sets. CoRR, abs/2101.02703, 2021. URL https://arxiv.org/abs/2101.02703
[2] Angelopoulos, Anastasios N., Stephen, Bates, Adam, Fisch, Lihua, Lei, and Tal, Schuster. “Conformal Risk Control.” (2022).
[3] Angelopoulos, A. N., Bates, S., Candès, E. J., Jordan, M. I., & Lei, L. (2021). Learn then test: “Calibrating predictive algorithms to achieve risk control”.