mapie.classification.SplitConformalClassifier
- class mapie.classification.SplitConformalClassifier(estimator: ClassifierMixin = LogisticRegression(), confidence_level: float | Iterable[float] = 0.9, conformity_score: str | BaseClassificationScore = 'lac', prefit: bool = True, n_jobs: int | None = None, verbose: int = 0, random_state: int | RandomState | None = None)[source]
Computes prediction sets using the split conformal classification technique:
The
fitmethod (optional) fits the base classifier to the training data.The
conformalizemethod estimates the uncertainty of the base classifier by computing conformity scores on the conformalization set.The
predict_setmethod predicts labels and sets of labels.
- Parameters:
- estimatorClassifierMixin, default=LogisticRegression()
The base classifier used to predict labels.
- confidence_levelUnion[float, List[float]], default=0.9
The confidence level(s) for the prediction sets, indicating the desired coverage probability of the prediction sets. If a float is provided, it represents a single confidence level. If a list, multiple prediction sets for each specified confidence level are returned.
- conformity_scoreUnion[str, BaseClassificationScore], default=”lac”
The method used to compute conformity scores.
Valid options:
“lac”
“top_k”
“aps”
“raps”
Any subclass of BaseClassificationScore
A custom score function inheriting from BaseClassificationScore may also be provided.
- prefitbool, default=True
If True, the base classifier must be fitted, and the
fitmethod must be skipped.If False, the base classifier will be fitted during the
fitmethod.- n_jobsOptional[int], default=None
The number of jobs to run in parallel when applicable.
- verboseint, default=0
Controls the verbosity level. Higher values increase the output details.
Examples
>>> from mapie.classification import SplitConformalClassifier >>> from mapie.utils import train_conformalize_test_split >>> from sklearn.datasets import make_classification >>> from sklearn.neighbors import KNeighborsClassifier
>>> X, y = make_classification(n_samples=500) >>> ( ... X_train, X_conformalize, X_test, ... y_train, y_conformalize, y_test ... ) = train_conformalize_test_split( ... X, y, train_size=0.6, conformalize_size=0.2, test_size=0.2, random_state=1 ... )
>>> mapie_classifier = SplitConformalClassifier( ... estimator=KNeighborsClassifier(), ... confidence_level=0.95, ... prefit=False, ... ).fit(X_train, y_train).conformalize(X_conformalize, y_conformalize)
>>> predicted_labels, predicted_sets = mapie_classifier.predict_set(X_test)
- __init__(estimator: ClassifierMixin = LogisticRegression(), confidence_level: float | Iterable[float] = 0.9, conformity_score: str | BaseClassificationScore = 'lac', prefit: bool = True, n_jobs: int | None = None, verbose: int = 0, random_state: int | RandomState | None = None) None[source]
- conformalize(X_conformalize: Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], y_conformalize: Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], predict_params: dict | None = None) SplitConformalClassifier[source]
Estimates the uncertainty of the base classifier by computing conformity scores on the conformalization set.
- Parameters:
- X_conformalizeArrayLike
Features of the conformalization set.
- y_conformalizeArrayLike
Targets of the conformalization set.
- predict_paramsOptional[dict], default=None
Parameters to pass to the
predictandpredict_probamethods of the base classifier. These parameters will also be used in thepredict_setandpredictmethods of this SplitConformalClassifier.
- Returns:
- Self
The conformalized SplitConformalClassifier instance.
- fit(X_train: Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], y_train: Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], fit_params: dict | None = None) SplitConformalClassifier[source]
Fits the base classifier to the training data.
- Parameters:
- X_trainArrayLike
Training data features.
- y_trainArrayLike
Training data targets.
- fit_paramsOptional[dict], default=None
Parameters to pass to the
fitmethod of the base classifier.
- Returns:
- Self
The fitted SplitConformalClassifier instance.
- predict(X: Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str]) ndarray[tuple[Any, ...], dtype[_ScalarT]][source]
For each sample in X, returns the predicted label by the base classifier.
- Parameters:
- XArrayLike
Features
- Returns:
- NDArray
Array of predicted labels, with shape
(n_samples,).
- predict_set(X: Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], conformity_score_params: dict | None = None) Tuple[ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]]][source]
For each sample in X, predicts a label (using the base classifier), and a set of labels.
If several confidence levels were provided during initialisation, several sets will be predicted for each sample. See the return signature.
- Parameters:
- XArrayLike
Features
- conformity_score_paramsOptional[dict], default=None
Parameters specific to conformity scores, used at prediction time.
The only example for now is
include_last_label, available for aps and raps conformity scores. For detailed information oninclude_last_label, see the docstring ofconformity_scores.sets.aps.APSConformityScore.get_prediction_sets().
- Returns:
- Tuple[NDArray, NDArray]
Two arrays:
Prediction labels, of shape
(n_samples,)Prediction sets, of shape
(n_samples, n_class, n_confidence_levels)
Examples using mapie.classification.SplitConformalClassifier
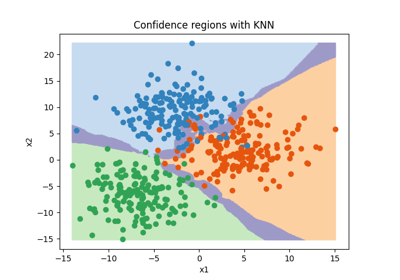
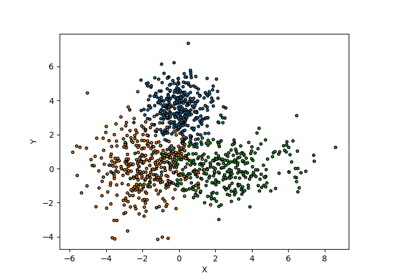
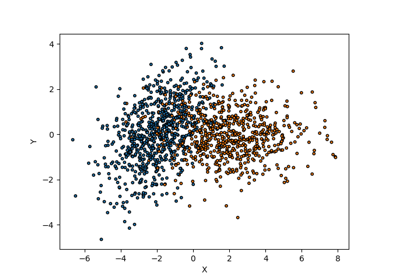
Set prediction example in the binary classification setting
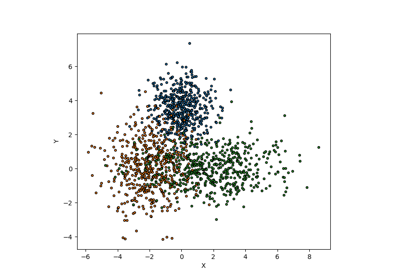
Least Ambiguous Set-Valued Classifiers with Bounded Error Levels, Sadinle et al. (2019)