Note
Click here to download the full example code
Group-conditional prediction intervals¶
This example shows how to use
:class:~mapie.conditional_conformal_prediction.ConditionalSplitConformalRegressor
to build prediction intervals with conditional guarantees on pre-defined
groups.
It is a simple companion to the Gibbs, Cherian and Candès (2023) reproduction
example in the scientific-articles gallery. Here, the goal is not to reproduce a
paper figure, but to isolate the main idea on a small synthetic regression
problem: define feature_map as group indicators, then compare marginal and
group-conditional calibration.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from mapie.conditional_conformal_prediction import ConditionalSplitConformalRegressor
from mapie.metrics.regression import (
regression_coverage_score,
regression_mean_width_score,
)
from mapie.regression import SplitConformalRegressor
from mapie.utils import train_conformalize_test_split
1. Generate grouped regression data¶
The first feature is a difficulty index split into three groups. The second feature controls the mean response. The conditional noise level increases with difficulty, so the same marginal prediction interval can overcover easy groups and undercover the hard group.
difficulty_bins = np.linspace(0, 1, 4)
group_noise = np.array([0.25, 0.80, 2.20])
def mean_function(signal):
return 2 * np.sin(signal) + 0.5 * signal
def generate_grouped_regression_data(n_samples=1600, random_state=42):
rng = np.random.default_rng(random_state)
difficulty = rng.uniform(0, 1, size=n_samples)
signal = rng.uniform(-3, 3, size=n_samples)
group = np.digitize(difficulty, difficulty_bins[1:-1], right=False)
noise = group_noise[group] * rng.normal(size=n_samples)
y = mean_function(signal) + noise
X = np.column_stack([difficulty, signal])
return X, y
X, y = generate_grouped_regression_data()
(
X_train,
X_conformalize,
X_test,
y_train,
y_conformalize,
y_test,
) = train_conformalize_test_split(
X,
y,
train_size=0.35,
conformalize_size=0.45,
test_size=0.20,
random_state=42,
)
2. Plot the data¶
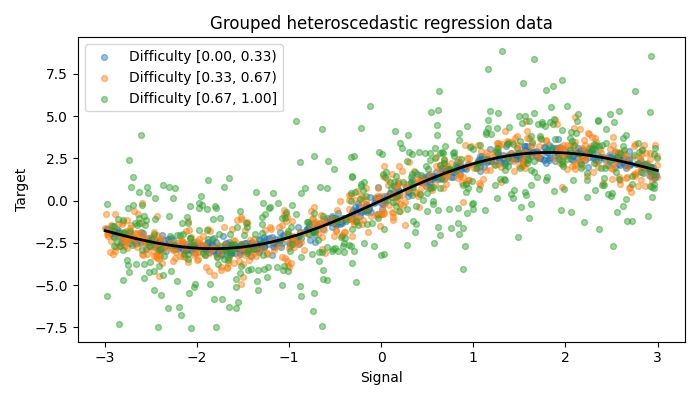
The scatter plot shows that all groups follow the same mean function, while high-difficulty samples have a much larger vertical spread.
group_indexes = np.digitize(X[:, 0], difficulty_bins[1:-1], right=False)
bin_labels = [
f"[{left:.2f}, {right:.2f})"
for left, right in zip(difficulty_bins[:-1], difficulty_bins[1:])
]
bin_labels[-1] = "[0.67, 1.00]"
fig, ax = plt.subplots(figsize=(7, 4))
for group_index, label in enumerate(bin_labels):
mask = group_indexes == group_index
ax.scatter(
X[mask, 1],
y[mask],
s=18,
alpha=0.45,
label=f"Difficulty {label}",
)
signal_grid = np.linspace(X[:, 1].min(), X[:, 1].max(), 300)
ax.plot(signal_grid, mean_function(signal_grid), color="black", linewidth=2)
ax.set_xlabel("Signal")
ax.set_ylabel("Target")
ax.set_title("Grouped heteroscedastic regression data")
ax.legend()
plt.tight_layout()
plt.show()
3. Define the conditional groups¶
feature_map returns one indicator column per difficulty group. The conditional
regressor uses these columns to calibrate score cutoffs that are valid on each
group, not only on average over the full distribution.
bin_centers = (difficulty_bins[:-1] + difficulty_bins[1:]) / 2
def indicator_matrix(values, bin_edges):
values = np.asarray(values).reshape(-1)
bin_indexes = np.digitize(values, bin_edges[1:-1], right=False)
matrix = np.zeros((len(values), len(bin_edges) - 1))
matrix[np.arange(len(values)), bin_indexes] = 1
return matrix
def phi_fn(X):
return indicator_matrix(np.asarray(X)[:, 0], difficulty_bins)
4. Fit marginal and conditional conformal regressors¶
Both methods use the same fitted polynomial regressor and the same
conformalization data. The marginal regressor uses one residual cutoff for all
samples, while ConditionalSplitConformalRegressor receives feature_map and
calibrates the cutoff by difficulty group.
confidence_level = 0.90
estimator = make_pipeline(PolynomialFeatures(degree=5), LinearRegression()).fit(
X_train, y_train
)
mapie_marginal = SplitConformalRegressor(
estimator=estimator,
confidence_level=confidence_level,
conformity_score="absolute",
prefit=True,
)
mapie_marginal.conformalize(X_conformalize, y_conformalize)
_, y_interval_marginal = mapie_marginal.predict_interval(X_test)
mapie_conditional = ConditionalSplitConformalRegressor(
phi_fn,
estimator=estimator,
confidence_level=confidence_level,
conformity_score="absolute",
prefit=True,
)
mapie_conditional.conformalize(X_conformalize, y_conformalize)
_, y_interval_conditional = mapie_conditional.predict_interval(X_test)
5. Evaluate and visualize the correction¶
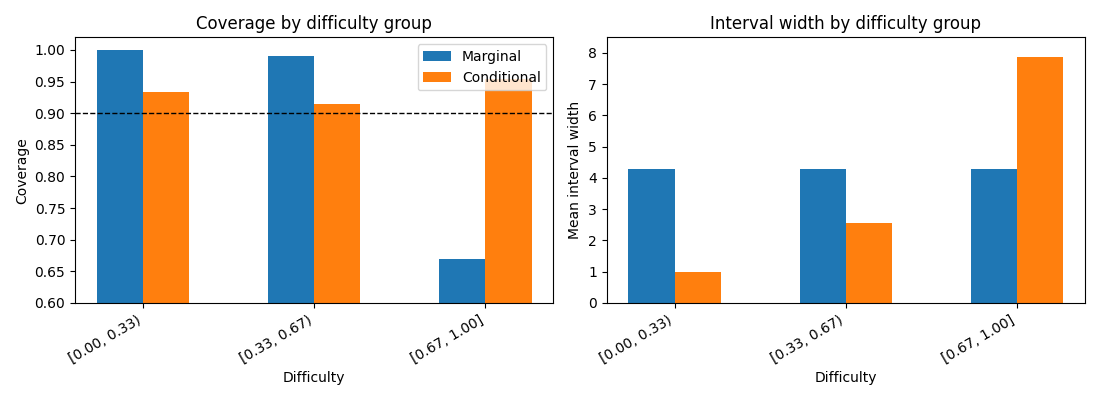
Marginal split conformal prediction has constant interval width with the absolute residual score. This overcovers the low-noise group and undercovers the high-noise group. Conditional conformal prediction makes an additional group-level correction, narrowing intervals for easy samples and widening them for difficult samples.
def group_mask(X, bin_index):
if bin_index == len(difficulty_bins) - 2:
return (X[:, 0] >= difficulty_bins[bin_index]) & (
X[:, 0] <= difficulty_bins[-1]
)
return (X[:, 0] >= difficulty_bins[bin_index]) & (
X[:, 0] < difficulty_bins[bin_index + 1]
)
def scores_by_group(y_true, intervals, X):
coverages = []
widths = []
for bin_index in range(len(difficulty_bins) - 1):
mask = group_mask(X, bin_index)
coverages.append(regression_coverage_score(y_true[mask], intervals[mask]))
widths.append(regression_mean_width_score(intervals[mask]))
return np.asarray(coverages).ravel(), np.asarray(widths).ravel()
coverage_marginal_by_group, width_marginal_by_group = scores_by_group(
y_test, y_interval_marginal, X_test
)
coverage_conditional_by_group, width_conditional_by_group = scores_by_group(
y_test, y_interval_conditional, X_test
)
fig, axes = plt.subplots(1, 2, figsize=(11, 4), sharex=True)
bar_width = 0.09
axes[0].bar(
bin_centers - bar_width / 2,
coverage_marginal_by_group,
width=bar_width,
label="Marginal",
)
axes[0].bar(
bin_centers + bar_width / 2,
coverage_conditional_by_group,
width=bar_width,
label="Conditional",
)
axes[0].axhline(confidence_level, color="black", linestyle="--", linewidth=1)
axes[0].set_ylim(0.60, 1.02)
axes[0].set_ylabel("Coverage")
axes[0].set_title("Coverage by difficulty group")
axes[0].legend()
axes[1].bar(
bin_centers - bar_width / 2,
width_marginal_by_group,
width=bar_width,
label="Marginal",
)
axes[1].bar(
bin_centers + bar_width / 2,
width_conditional_by_group,
width=bar_width,
label="Conditional",
)
axes[1].set_ylim(0.0, 8.5)
axes[1].set_ylabel("Mean interval width")
axes[1].set_title("Interval width by difficulty group")
for ax in axes:
ax.set_xlabel("Difficulty")
ax.set_xticks(bin_centers)
ax.set_xticklabels(bin_labels, rotation=30, ha="right")
plt.tight_layout()
plt.show()
Total running time of the script: ( 0 minutes 1.005 seconds)
Download Python source code: plot_conditional_conformal_regression_groups.py
Download Jupyter notebook: plot_conditional_conformal_regression_groups.ipynb