Note
Go to the end to download the full example code.
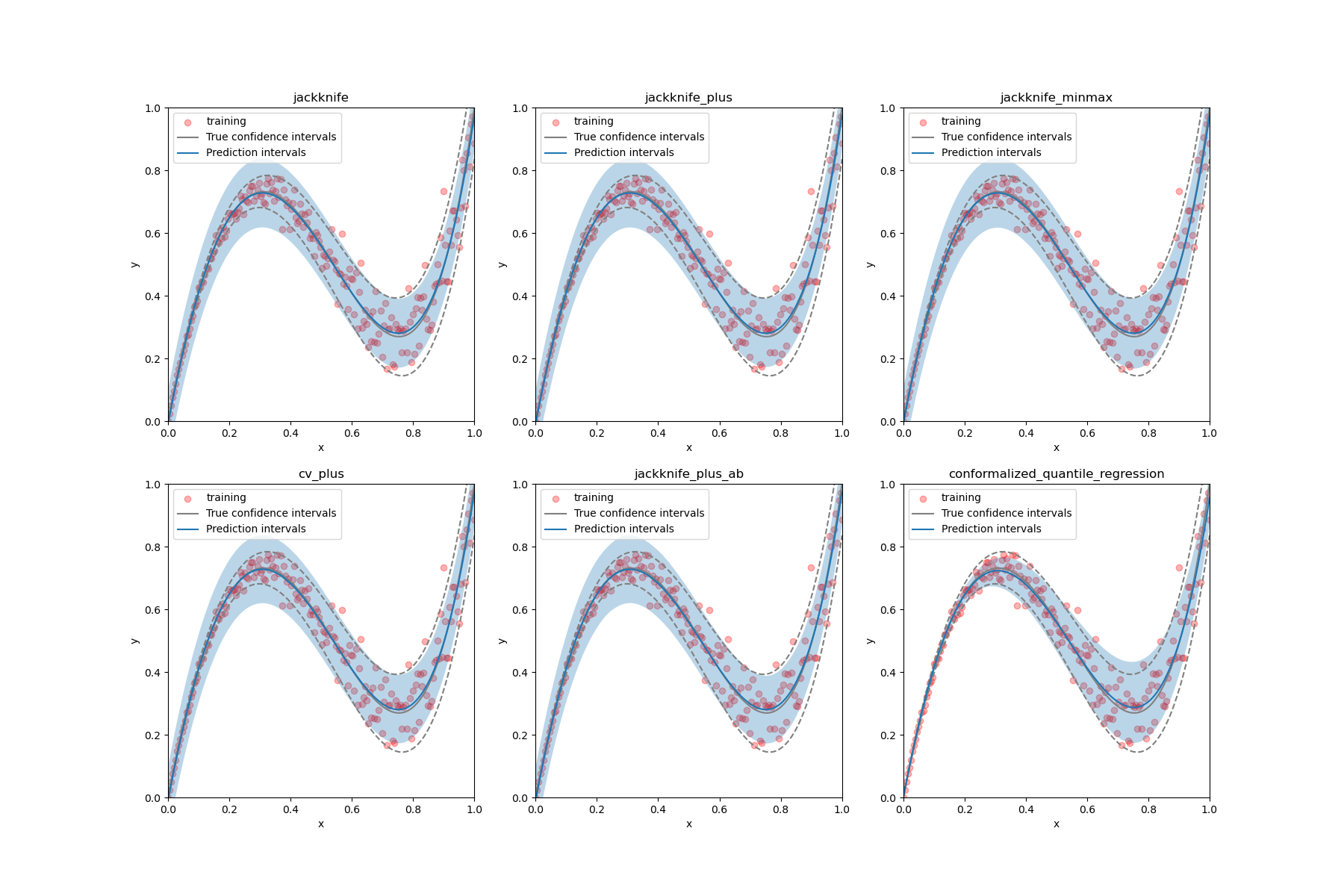
Data with uneven uncertainty
CrossConformalRegressor, JackknifeAfterBootstrapRegressor, ConformalizedQuantileRegressor are used to estimate the prediction intervals of 1D heteroscedastic data using different strategies.
The example clearly shows that ConformalizedQuantileRegressor should provide the same coverage for a lower width of intervals because it adapts the prediction intervals to the local heteroscedastic noise.
from typing import Tuple
import numpy as np
import scipy
from matplotlib import pyplot as plt
from numpy.typing import NDArray
from sklearn.linear_model import LinearRegression, QuantileRegressor
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from mapie.regression import (
ConformalizedQuantileRegressor,
CrossConformalRegressor,
JackknifeAfterBootstrapRegressor,
)
RANDOM_STATE = 42
def f(x: NDArray) -> NDArray:
"""Polynomial function used to generate one-dimensional data"""
return np.array(5 * x + 5 * x**4 - 9 * x**2)
def get_heteroscedastic_data(
n_train: int = 200, n_true: int = 200, sigma: float = 0.1
) -> Tuple[NDArray, NDArray, NDArray, NDArray, NDArray]:
"""
Generate one-dimensional data from a given function,
number of training and test samples and a given standard
deviation increases linearly with x.
The training data data is generated from an exponential distribution.
Parameters
----------
n_train : int, optional
Number of training samples, by default 200.
n_true : int, optional
Number of test samples, by default 1000.
sigma : float, optional
Standard deviation of noise, by default 0.1
Returns
-------
Tuple[NDArray, NDArray, NDArray, NDArray, NDArray]
Generated training and test data.
[0]: X_train
[1]: y_train
[2]: X_true
[3]: y_true
[4]: y_true_sigma
"""
np.random.seed(RANDOM_STATE)
q95 = scipy.stats.norm.ppf(0.95)
X_train = np.linspace(0, 1, n_train)
X_true = np.linspace(0, 1, n_true)
y_train = f(X_train) + np.random.normal(0, sigma, n_train) * X_train
y_true = f(X_true)
y_true_sigma = q95 * sigma * X_true
return X_train.reshape(-1, 1), y_train, X_true.reshape(-1, 1), y_true, y_true_sigma
def plot_1d_data(
X_train: NDArray,
y_train: NDArray,
X_test: NDArray,
y_test: NDArray,
y_test_sigma: NDArray,
y_pred: NDArray,
y_pred_low: NDArray,
y_pred_up: NDArray,
ax: plt.Axes,
title: str,
) -> None:
"""
Generate a figure showing the training data and estimated
prediction intervals on test data.
Parameters
----------
X_train : NDArray
Training data.
y_train : NDArray
Training labels.
X_test : NDArray
Test data.
y_test : NDArray
True function values on test data.
y_test_sigma : float
True standard deviation.
y_pred : NDArray
Predictions on test data.
y_pred_low : NDArray
Predicted lower bounds on test data.
y_pred_up : NDArray
Predicted upper bounds on test data.
ax : plt.Axes
Axis to plot.
title : str
Title of the figure.
"""
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_xlim([0, 1])
ax.set_ylim([0, 1])
ax.scatter(X_train, y_train, color="red", alpha=0.3, label="training")
ax.plot(X_test, y_test, color="gray", label="True confidence intervals")
ax.plot(X_test, y_test - y_test_sigma, color="gray", ls="--")
ax.plot(X_test, y_test + y_test_sigma, color="gray", ls="--")
ax.plot(X_test, y_pred, label="Prediction intervals")
ax.fill_between(X_test, y_pred_low, y_pred_up, alpha=0.3)
ax.set_title(title)
ax.legend()
X_train_conformalize, y_train_conformalize, X_test, y_test, y_test_sigma = (
get_heteroscedastic_data()
)
polyn_model = Pipeline(
[
("poly", PolynomialFeatures(degree=4)),
("linear", LinearRegression()),
]
)
polyn_model_quant = Pipeline(
[
("poly", PolynomialFeatures(degree=4)),
(
"linear",
QuantileRegressor(
solver="highs-ds",
alpha=0,
),
),
]
)
STRATEGIES = {
"cv_plus": {
"class": CrossConformalRegressor,
"init_params": dict(method="plus", cv=10),
},
"jackknife": {
"class": CrossConformalRegressor,
"init_params": dict(method="base", cv=-1),
},
"jackknife_plus": {
"class": CrossConformalRegressor,
"init_params": dict(method="plus", cv=-1),
},
"jackknife_minmax": {
"class": CrossConformalRegressor,
"init_params": dict(method="minmax", cv=-1),
},
"jackknife_plus_ab": {
"class": JackknifeAfterBootstrapRegressor,
"init_params": dict(method="plus", resampling=50),
},
"conformalized_quantile_regression": {
"class": ConformalizedQuantileRegressor,
"init_params": dict(),
},
}
fig, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(2, 3, figsize=(3 * 6, 12))
axs = [ax1, ax2, ax3, ax4, ax5, ax6]
for i, (strategy_name, strategy_params) in enumerate(STRATEGIES.items()):
init_params = strategy_params["init_params"]
class_ = strategy_params["class"]
if strategy_name == "conformalized_quantile_regression":
X_train, X_conformalize, y_train, y_conformalize = train_test_split(
X_train_conformalize,
y_train_conformalize,
test_size=0.3,
random_state=RANDOM_STATE,
)
mapie = class_(polyn_model_quant, confidence_level=0.95, **init_params)
mapie.fit(X_train, y_train)
mapie.conformalize(X_conformalize, y_conformalize)
y_pred, y_pis = mapie.predict_interval(X_test)
else:
mapie = class_(
polyn_model, confidence_level=0.95, random_state=RANDOM_STATE, **init_params
)
mapie.fit_conformalize(X_train_conformalize, y_train_conformalize)
y_pred, y_pis = mapie.predict_interval(X_test)
plot_1d_data(
X_train_conformalize.ravel(),
y_train_conformalize,
X_test.ravel(),
y_test,
y_test_sigma,
y_pred,
y_pis[:, 0, 0],
y_pis[:, 1, 0],
axs[i],
strategy_name,
)
plt.show()
Total running time of the script: (0 minutes 6.443 seconds)