Note
Go to the end to download the full example code.
Focus on local (or “conditional”) coverage
This example uses SplitConformalRegressor, JackknifeAfterBootstrapRegressor, with conformal scores that returns adaptive intervals i.e. (GammaConformityScore and ResidualNormalisedScore) as well as ConformalizedQuantileRegressor and ` The conditional coverage is computed with the three functions that allows to estimate the conditional coverage in regression regression_ssc, regression_ssc_score and hsic.
import warnings
from typing import Tuple, Union
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split
from numpy.typing import NDArray
from mapie.conformity_scores import GammaConformityScore, ResidualNormalisedScore
from mapie.metrics.regression import (
regression_coverage_score,
regression_ssc,
regression_ssc_score,
hsic,
)
from mapie.regression import (
SplitConformalRegressor,
CrossConformalRegressor,
JackknifeAfterBootstrapRegressor,
ConformalizedQuantileRegressor,
)
warnings.filterwarnings("ignore")
RANDOM_STATE = 42
split_size = 0.20
alpha = 0.05
rng = np.random.default_rng(RANDOM_STATE)
# Functions for generating our dataset
def sin_with_controlled_noise(
min_x: Union[int, float],
max_x: Union[int, float],
n_samples: int,
) -> Tuple[NDArray, NDArray]:
"""
Generate a dataset following sinx except that one interval over two 1 or -1
(0.5 probability) is added to X
Parameters
----------
min_x: Union[int, float]
The minimum value for X.
max_x: Union[int, float]
The maximum value for X.
n_samples: int
The number of samples wanted in the dataset.
Returns
-------
Tuple[NDArray, NDArray]
- X: feature data.
- y: target data
"""
X = rng.uniform(min_x, max_x, size=(n_samples, 1)).astype(np.float32)
y = np.zeros(shape=(n_samples,))
for i in range(int(max_x) + 1):
indexes = np.argwhere(np.greater_equal(i, X) * np.greater(X, i - 1))
if i % 2 == 0:
for index in indexes:
noise = rng.choice([-1, 1])
y[index] = np.sin(X[index][0]) + noise * rng.random() + 2
else:
for index in indexes:
y[index] = np.sin(X[index][0]) + rng.random() / 5 + 2
return X, y
# Data generation
min_x, max_x, n_samples = 0, 10, 3000
X_train_conformalize, y_train_conformalize = sin_with_controlled_noise(
min_x, max_x, n_samples
)
X_test, y_test = sin_with_controlled_noise(min_x, max_x, int(n_samples * split_size))
# Definition of our base models
model = LGBMRegressor(random_state=RANDOM_STATE, alpha=0.5)
model_quant = LGBMRegressor(objective="quantile", alpha=0.5, random_state=RANDOM_STATE)
# Definition of the experimental set up
STRATEGIES = {
"cv_plus": {
"class": CrossConformalRegressor,
"init_params": dict(method="plus", cv=10),
},
"jackknife_plus_ab": {
"class": JackknifeAfterBootstrapRegressor,
"init_params": dict(
method="plus",
resampling=100,
conformity_score=GammaConformityScore(),
),
},
"residual_normalised": {
"class": SplitConformalRegressor,
"init_params": dict(
prefit=False,
conformity_score=ResidualNormalisedScore(
residual_estimator=LGBMRegressor(alpha=0.5, random_state=RANDOM_STATE),
split_size=0.7,
random_state=RANDOM_STATE,
),
),
},
"conformalized_quantile_regression": {
"class": ConformalizedQuantileRegressor,
"init_params": dict(),
},
}
y_pred, y_pis, coverage, cond_coverage, coef_corr = {}, {}, {}, {}, {}
num_bins = 10
for strategy_name, strategy_params in STRATEGIES.items():
init_params = strategy_params["init_params"]
class_ = strategy_params["class"]
if strategy_name in ["conformalized_quantile_regression", "residual_normalised"]:
X_train, X_conformalize, y_train, y_conformalize = train_test_split(
X_train_conformalize,
y_train_conformalize,
test_size=0.3,
random_state=RANDOM_STATE,
)
mapie = class_(model_quant, confidence_level=0.95, **init_params)
mapie.fit(X_train, y_train)
mapie.conformalize(X_conformalize, y_conformalize)
y_pred[strategy_name], y_pis[strategy_name] = mapie.predict_interval(X_test)
else:
mapie = class_(
model, confidence_level=0.95, random_state=RANDOM_STATE, **init_params
)
mapie.fit_conformalize(X_train_conformalize, y_train_conformalize)
y_pred[strategy_name], y_pis[strategy_name] = mapie.predict_interval(X_test)
# computing metrics
coverage[strategy_name] = regression_coverage_score(y_test, y_pis[strategy_name])
cond_coverage[strategy_name] = regression_ssc_score(
y_test, y_pis[strategy_name], num_bins=1
)
coef_corr[strategy_name] = hsic(y_test, y_pis[strategy_name])
# Visualisation of the estimated conditional coverage
estimated_cond_cov = pd.DataFrame(
columns=["global coverage", "max coverage violation", "hsic"],
index=STRATEGIES.keys(),
)
for m, cov, ssc, coef in zip(
STRATEGIES.keys(), coverage.values(), cond_coverage.values(), coef_corr.values()
):
estimated_cond_cov.loc[m] = [round(cov[0], 2), round(ssc[0], 2), round(coef[0], 2)]
with pd.option_context("display.max_rows", None, "display.max_columns", None):
print(estimated_cond_cov)
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000062 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.236940
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000048 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.238454
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000049 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.241043
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000052 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.233609
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000049 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.237100
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000062 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.243047
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000048 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.227147
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000052 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.235667
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000049 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.234801
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000053 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.244449
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000051 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2700, number of used features: 1
[LightGBM] [Info] Start training from score 2.234082
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.005082 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.236940
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000053 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.236541
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.212973
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.246608
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.220391
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.251966
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.261881
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.226235
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.232120
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000052 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.242840
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000053 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.232683
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000049 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.230536
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.250654
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.215282
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.233282
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.241476
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.222148
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.001711 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.223060
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000073 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.235168
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.240134
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.221829
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000059 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.240449
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000059 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.228365
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000060 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.226862
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.226322
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.239035
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.227012
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000059 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.265971
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000060 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.239984
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000059 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.236110
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000060 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.252169
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000060 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.239297
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.246145
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.245928
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.006099 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.219032
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.223940
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.001685 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.243588
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000052 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.272210
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000048 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.249186
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000051 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.230618
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.224350
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.249118
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.264239
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.237456
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.226675
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000053 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.206534
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.252650
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.252081
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.234150
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000059 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.239420
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.245076
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.003838 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.245001
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.228583
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.258920
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.211434
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000061 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.254719
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.218685
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000078 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.238075
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.234096
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000060 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.237550
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.217085
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.240428
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.243736
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.004106 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.218546
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.242217
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.240419
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.214384
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.229694
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000054 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.229758
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.226040
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.211825
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.246180
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000059 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.257792
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000061 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.229666
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.226681
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000059 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.229388
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.248947
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.229004
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.204857
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.245111
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.240490
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.213861
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000059 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.225568
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000055 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.227180
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.231144
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.239371
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.246461
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.227213
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.227162
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.241863
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.003082 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.247330
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.235548
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.235062
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.234578
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.232585
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.002900 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.261106
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000077 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.225196
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.234579
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000056 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.252317
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000057 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.219942
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000058 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 3000, number of used features: 1
[LightGBM] [Info] Start training from score 2.237903
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000048 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2100, number of used features: 1
[LightGBM] [Info] Start training from score 2.387946
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000028 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 211
[LightGBM] [Info] Number of data points in the train set: 630, number of used features: 1
[LightGBM] [Info] Start training from score -2.110152
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000047 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2100, number of used features: 1
[LightGBM] [Info] Start training from score 0.676877
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000044 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2100, number of used features: 1
[LightGBM] [Info] Start training from score 3.674894
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000047 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 255
[LightGBM] [Info] Number of data points in the train set: 2100, number of used features: 1
[LightGBM] [Info] Start training from score 2.387946
global coverage max coverage violation hsic
cv_plus 0.95 0.95 0.0
jackknife_plus_ab 0.94 0.94 0.05
residual_normalised 0.97 0.97 0.01
conformalized_quantile_regression 0.93 0.93 0.03
The global coverage is similar for all methods. To determine if these methods are good adaptive conformal methods, we use two metrics: regression_ssc_score and hsic.
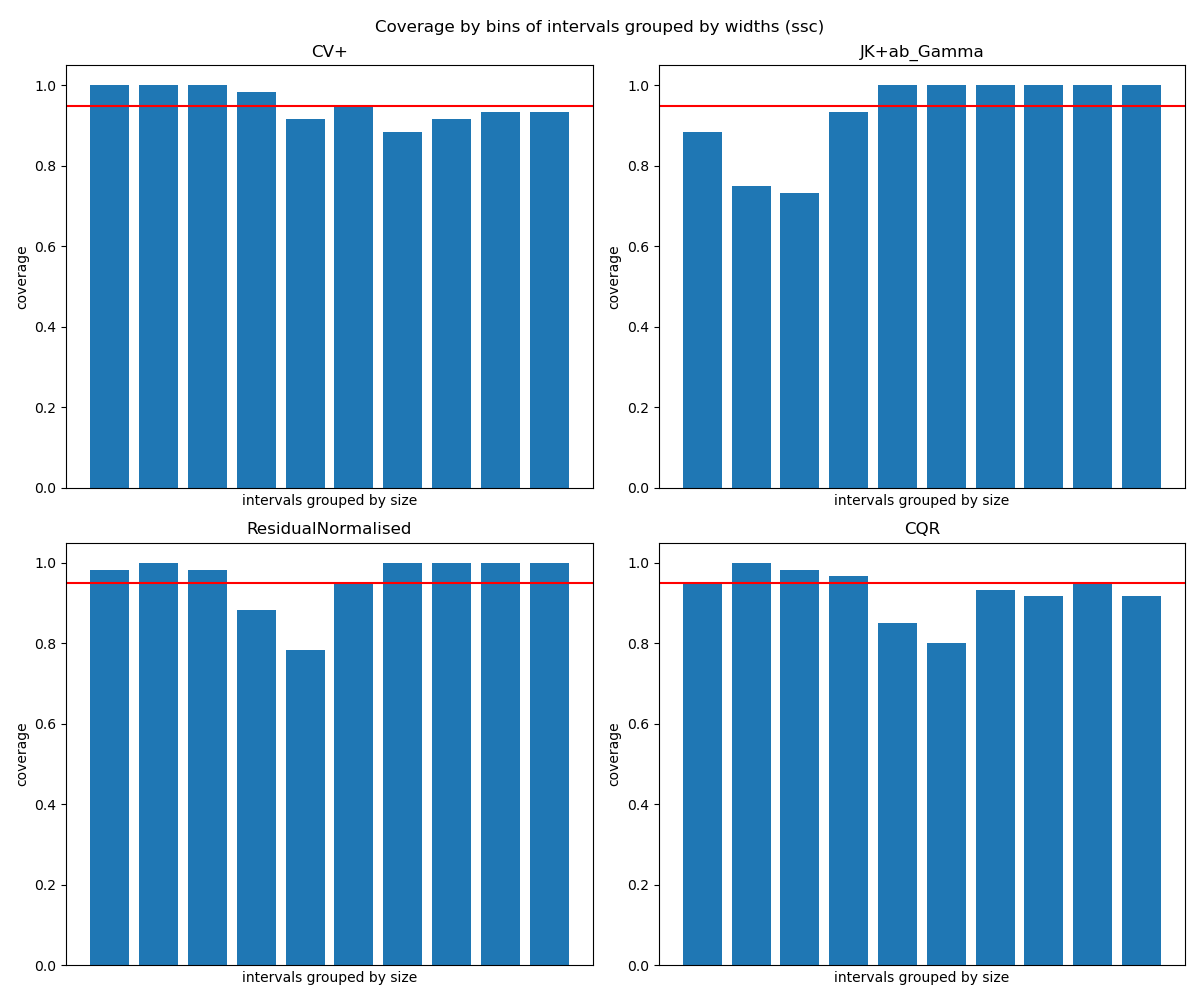
SSC (Size Stratified Coverage): This measures the maximum violation of coverage by grouping intervals by width and computing coverage for each group. An adaptive method has a maximum violation close to the global coverage. Among the four methods, CV+ performs the best.
HSIC (Hilbert-Schmidt Independence Criterion): This computes the correlation between coverage and interval size. A value of 0 indicates independence between the two.
It’s important to note that CV+ with the absolute residual score calculates constant intervals, which are not adaptive. Therefore, checking the distribution of interval widths is crucial before drawing conclusions.
In this example, none of the methods stand out with the HSIC correlation coefficient. However, the SSC score for the gamma score method is significantly worse than for CQR and ResidualNormalisedScore, despite similar global coverage. ResidualNormalisedScore and CQR are very close, with ResidualNormalisedScore being slightly more conservative.
# Visualition of the data and predictions
def plot_intervals(X, y, y_pred, intervals, title="", ax=None):
"""
Plots the data X, y with associated intervals and predictions points.
Parameters
----------
X: ArrayLike
Observed features
y: ArrayLike
Observed targets
y_pred: ArrayLike
Predictions
intervals: ArrayLike
Prediction intervals
title: str
Title of the plot
ax: matplotlib axes
An ax can be provided to include this plot in a subplot
"""
if ax is None:
fig, ax = plt.subplots(figsize=(6, 5))
y_pred = y_pred.reshape((X.shape[0], 1))
order = np.argsort(X[:, 0])
# data
ax.scatter(X.ravel(), y, color="#1f77b4", alpha=0.3, label="data")
# predictions
ax.scatter(
X.ravel(), y_pred, color="#ff7f0e", marker="+", label="predictions", alpha=0.5
)
# intervals
for i in range(intervals.shape[-1]):
ax.fill_between(
X[order].ravel(),
intervals[:, 0, i][order],
intervals[:, 1, i][order],
color="#ff7f0e",
alpha=0.3,
)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_title(title)
ax.legend()
def plot_coverage_by_width(y, intervals, num_bins, alpha, title="", ax=None):
"""
PLots a bar diagram of coverages by groups of interval widths.
Parameters
----------
y: ArrayLike
Observed targets.
intervals: ArrayLike
Intervals of prediction
num_bins: int
Number of groups of interval widths
alpha: float
The risk level
title: str
Title of the plot
ax: matplotlib axes
An ax can be provided to include this plot in a subplot
"""
if ax is None:
fig, ax = plt.subplots(figsize=(6, 5))
ax.bar(np.arange(num_bins), regression_ssc(y, intervals, num_bins=num_bins)[0])
ax.axhline(y=1 - alpha, color="r", linestyle="-")
ax.set_title(title)
ax.set_xlabel("intervals grouped by size")
ax.set_ylabel("coverage")
ax.tick_params(axis="x", which="both", bottom=False, top=False, labelbottom=False)
max_width = np.max(
[
np.abs(y_pis[strategy][:, 0, 0] - y_pis[strategy][:, 1, 0])
for strategy in STRATEGIES.keys()
]
)
fig_distr, axs_distr = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
fig_viz, axs_viz = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
fig_hist, axs_hist = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
for ax_viz, ax_hist, ax_distr, strategy in zip(
axs_viz.flat, axs_hist.flat, axs_distr.flat, STRATEGIES.keys()
):
plot_intervals(
X_test, y_test, y_pred[strategy], y_pis[strategy], title=strategy, ax=ax_viz
)
plot_coverage_by_width(
y_test,
y_pis[strategy],
num_bins=num_bins,
alpha=alpha,
title=strategy,
ax=ax_hist,
)
ax_distr.hist(
np.abs(y_pis[strategy][:, 0, 0] - y_pis[strategy][:, 1, 0]), bins=num_bins
)
ax_distr.set_xlabel("Interval width")
ax_distr.set_ylabel("Occurences")
ax_distr.set_title(strategy)
ax_distr.set_xlim([0, max_width])
fig_viz.suptitle("Predicted points and intervals on test data")
fig_distr.suptitle("Distribution of intervals widths")
fig_hist.suptitle("Coverage by bins of intervals grouped by widths (ssc)")
plt.tight_layout()
plt.show()
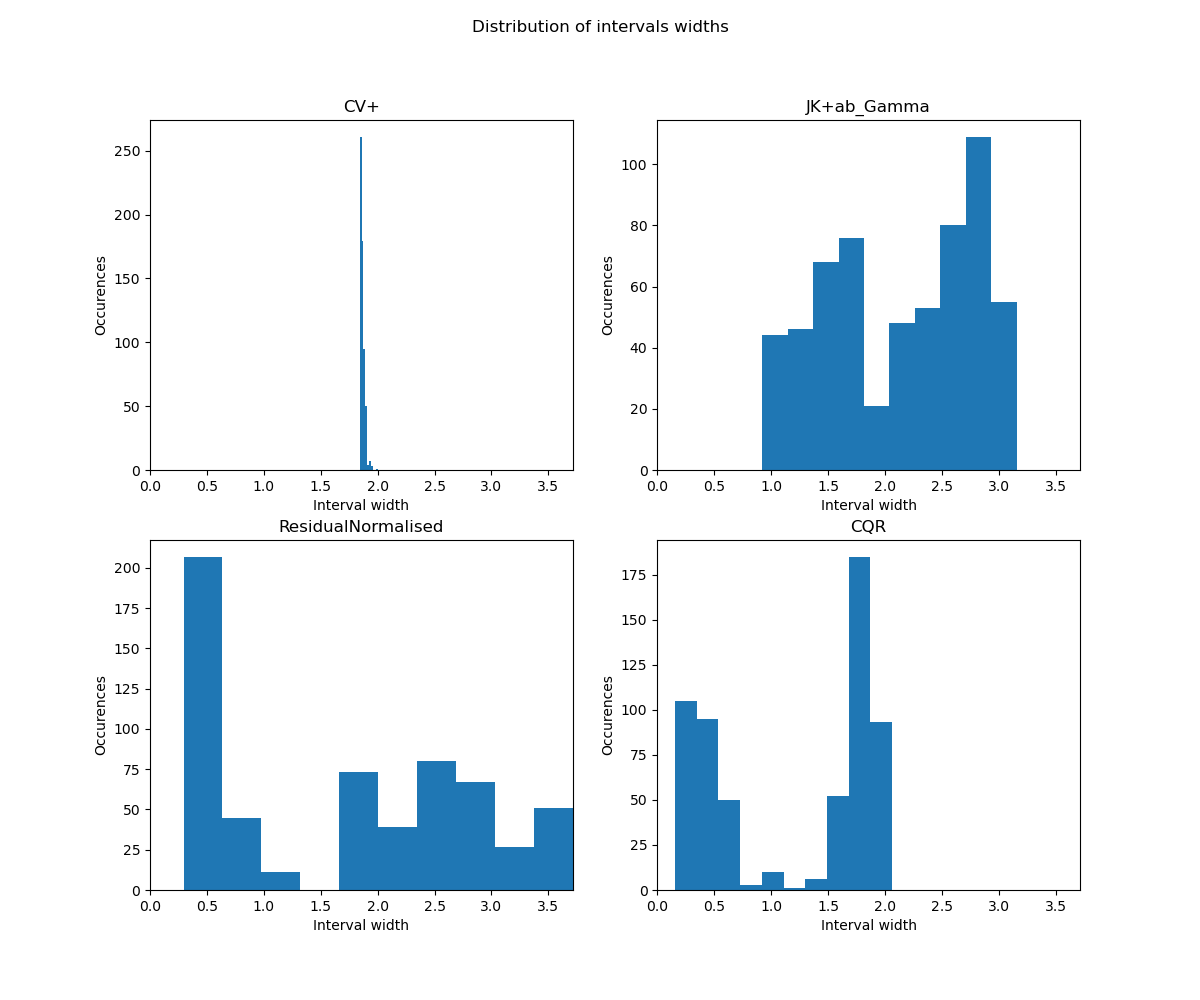
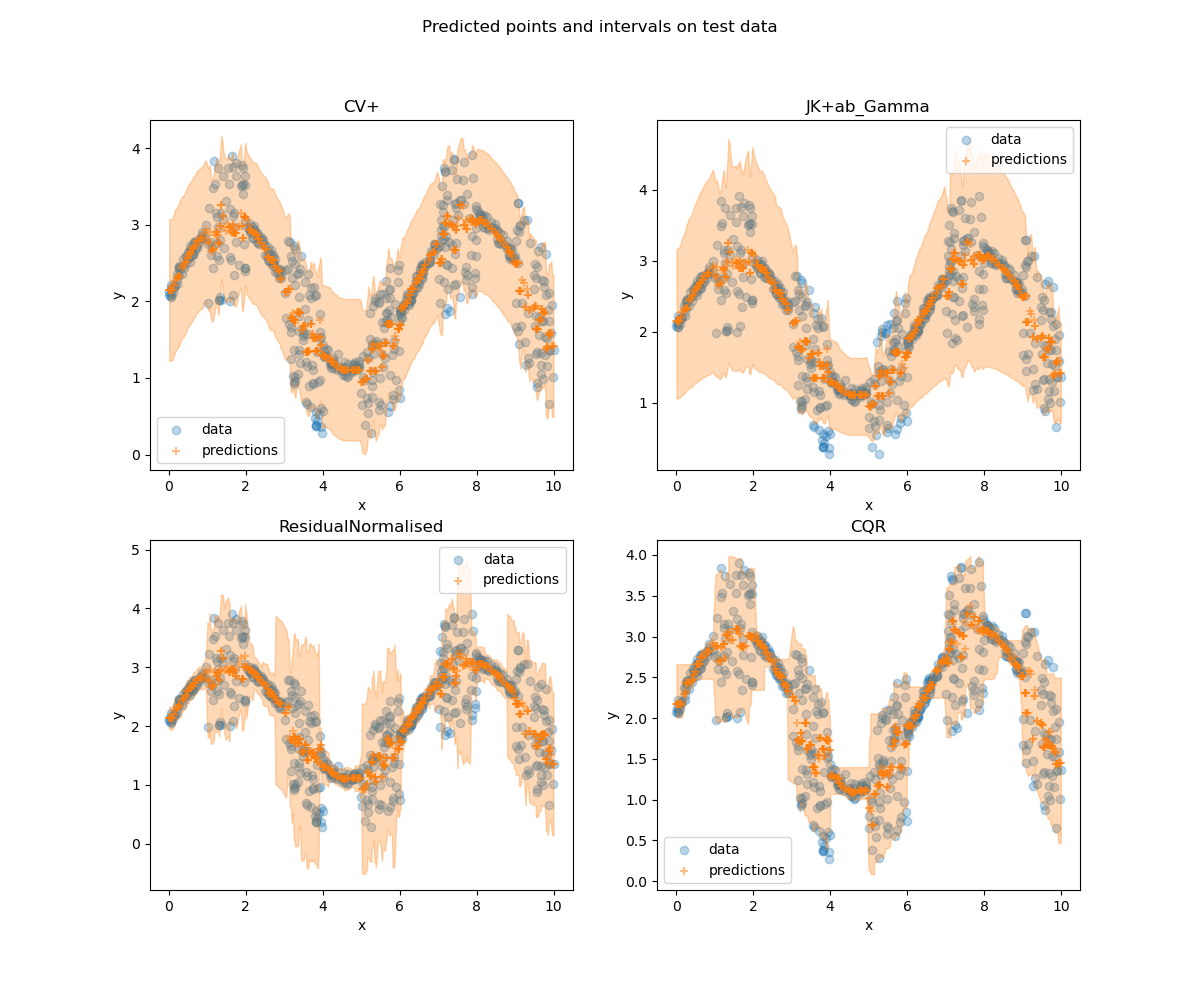
With toy datasets, it’s easy to visually compare methods using data and prediction plots. A histogram of interval widths is crucial to accompany the metrics. This histogram shows that CV+ is not adaptive, so the metrics should not be used to evaluate its adaptivity. A wider spread of intervals indicates a more adaptive method.
The plot of coverage by bins of intervals grouped by widths (output of regression_ssc) should show bins as constant as possible around the global coverage (0.9).
# The gamma score does not perform well in size stratified coverage,
# often over-covering or under-covering. ResidualNormalisedScore has
# several bins with over-coverage, while CQR has more under-coverage.
# Visualizing the data confirms these results: CQR performs better
# with spread-out data, whereas ResidualNormalisedScore is better
# with small intervals.
Total running time of the script: (0 minutes 27.100 seconds)