mapie.regression.JackknifeAfterBootstrapRegressor
- class mapie.regression.JackknifeAfterBootstrapRegressor(estimator: RegressorMixin = LinearRegression(), confidence_level: float | Iterable[float] = 0.9, conformity_score: str | BaseRegressionScore = 'absolute', method: str = 'plus', resampling: int | Subsample = 30, aggregation_method: str = 'mean', n_jobs: int | None = None, verbose: int = 0, random_state: int | RandomState | None = None)[source]
Computes prediction intervals using the jackknife-after-bootstrap technique:
The fit_conformalize method estimates the uncertainty of the base regressor using bootstrap sampling. It fits the base regressor on samples of the dataset and computes conformity scores on the out-of-sample data.
The predict_interval computes prediction points and intervals.
- Parameters:
- estimatorRegressorMixin, default=LinearRegression()
The base regressor used to predict points.
- confidence_levelUnion[float, List[float]], default=0.9
The confidence level(s) for the prediction intervals, indicating the desired coverage probability of the prediction intervals. If a float is provided, it represents a single confidence level. If a list, multiple prediction intervals for each specified confidence level are returned.
- conformity_scoreUnion[str, BaseRegressionScore], default=”absolute”
The method used to compute conformity scores
Valid options:
“absolute”
“gamma”
The corresponding subclasses of BaseRegressionScore
A custom score function inheriting from BaseRegressionScore may also be provided.
See [theoretical description (conformity scores)](../theory/conformity-scores.md).
- methodstr, default=”plus”
The method used to compute prediction intervals. Options are:
“plus”: Based on the conformity scores from each bootstrap sample and the testing prediction.
“minmax”: Based on the minimum and maximum conformity scores from each bootstrap sample.
Note: The “base” method is not mentioned in the conformal inference literature for Jackknife after bootstrap strategies, hence not provided here.
- resamplingUnion[int, Subsample], default=30
Number of bootstrap resamples or an instance of Subsample for custom sampling strategy.
- aggregation_methodstr, default=”mean”
Aggregation method for predictions across bootstrap samples. Options:
“mean”
“median”
- n_jobsOptional[int], default=None
The number of jobs to run in parallel when applicable.
- verboseint, default=0
Controls the verbosity level. Higher values increase the output details.
- random_stateOptional[Union[int, np.random.RandomState]], default=None
A seed or random state instance to ensure reproducibility in any random operations within the regressor.
Examples
>>> from mapie.regression import JackknifeAfterBootstrapRegressor >>> from sklearn.datasets import make_regression >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import Ridge
>>> X_full, y_full = make_regression(n_samples=500,n_features=2,noise=1.0) >>> X, X_test, y, y_test = train_test_split(X_full, y_full)
>>> mapie_regressor = JackknifeAfterBootstrapRegressor( ... estimator=Ridge(), ... confidence_level=0.95, ... resampling=25, ... ).fit_conformalize(X, y)
>>> predicted_points, predicted_intervals = mapie_regressor.predict_interval(X_test)
- __init__(estimator: RegressorMixin = LinearRegression(), confidence_level: float | Iterable[float] = 0.9, conformity_score: str | BaseRegressionScore = 'absolute', method: str = 'plus', resampling: int | Subsample = 30, aggregation_method: str = 'mean', n_jobs: int | None = None, verbose: int = 0, random_state: int | RandomState | None = None) None[source]
- property conformity_scores: ndarray[tuple[Any, ...], dtype[_ScalarT]]
Returns the conformity scores computed by the fit_conformalize method, on the out-of-fold predictions produced during cross-validation.
- Returns:
- NDArray
Array of conformity scores, with shape (n_samples,).
- fit_conformalize(X: ArrayLike, y: ArrayLike, fit_params: dict | None = None, predict_params: dict | None = None) JackknifeAfterBootstrapRegressor[source]
Estimates the uncertainty of the base regressor using bootstrap sampling: fits the base regressor on (potentially overlapping) samples of the dataset, and computes conformity scores on the corresponding out of samples data.
If called on an instance that has already been fitted, a UserWarning is emitted and the previously computed conformity scores are discarded before the new fit. Call reset() explicitly to suppress the warning.
- Parameters:
- XArrayLike
Features. Must be the same X used in .fit
- yArrayLike
Targets. Must be the same y used in .fit
- fit_paramsOptional[dict], default=None
Parameters to pass to the fit method of the base regressor.
- predict_paramsOptional[dict], default=None
Parameters to pass to the predict method of the base regressor. These parameters will also be used in the predict_interval and predict methods of this JackknifeAfterBootstrapRegressor.
- Returns:
- Self
This JackknifeAfterBootstrapRegressor instance, fitted and conformalized.
- predict(X: ArrayLike, aggregate_point_predictions: bool = True, ensemble: Any = _UNSET) ndarray[tuple[Any, ...], dtype[_ScalarT]][source]
Predicts points.
By default, points are predicted using an aggregation. See the aggregate_point_predictions parameter.
- Parameters:
- XArrayLike
Data features for generating point predictions.
- aggregate_point_predictionsbool, default=True
If True, a predicted point is an aggregation of the predictions of the regressors trained on each bootstrap samples. This aggregation depends on the aggregation_method provided during initialisation. If False, a point is predicted using the regressor trained on the entire data
- ensemblebool
Deprecated since version Renamed: to aggregate_point_predictions. Passing ensemble still works but emits a FutureWarning and will be removed in a future release.
- Returns:
- NDArray
Array of point predictions, with shape (n_samples,).
- predict_interval(X: ArrayLike, aggregate_point_predictions: bool = True, minimize_interval_width: bool = False, allow_infinite_bounds: bool = False, ensemble: Any = _UNSET) Tuple[ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]]][source]
Predicts points and intervals.
If several confidence levels were provided during initialisation, several intervals will be predicted for each sample. See the return signature.
By default, points are predicted using an aggregation. See the aggregate_point_predictions parameter.
- Parameters:
- XArrayLike
Test data for prediction intervals.
- aggregate_point_predictionsbool, default=True
If True, a predicted point is an aggregation of the predictions of the regressors trained on each bootstrap samples. This aggregation depends on the aggregation_method provided during initialisation.
If False, a point is predicted using the regressor trained on the entire data
- minimize_interval_widthbool, default=False
If True, attempts to minimize the interval width.
- allow_infinite_boundsbool, default=False
If True, allows prediction intervals with infinite bounds.
- ensemblebool
Deprecated since version Renamed: to aggregate_point_predictions. Passing ensemble still works but emits a FutureWarning and will be removed in a future release.
- Returns:
- Tuple[NDArray, NDArray]
Two arrays:
Prediction points, of shape (n_samples,)
Prediction intervals, of shape (n_samples, 2, n_confidence_levels)
- reset() JackknifeAfterBootstrapRegressor[source]
Discard previously computed conformity scores so that fit_conformalize can be called again with new data.
- Returns:
- Self
This JackknifeAfterBootstrapRegressor instance, reset to its pre-fit state.
Examples using mapie.regression.JackknifeAfterBootstrapRegressor
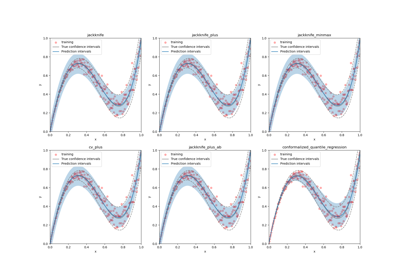
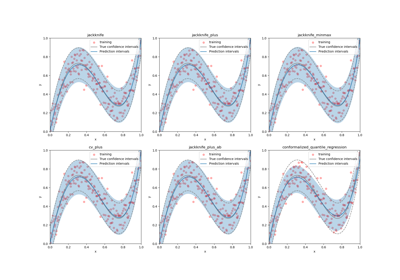
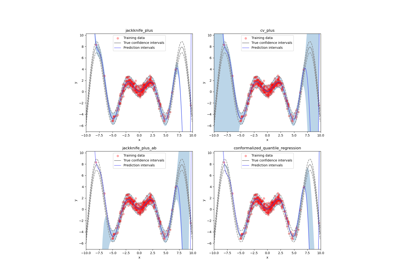
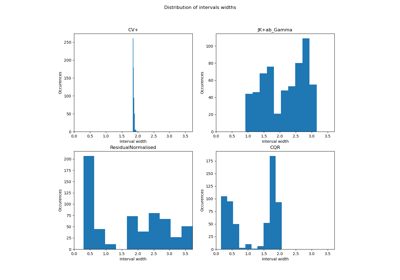
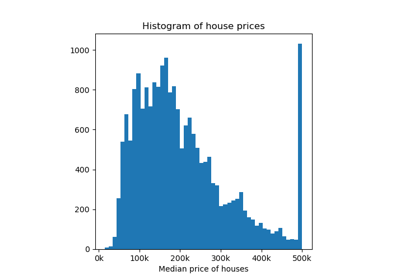
Conformalized quantile regression on gamma distributed data
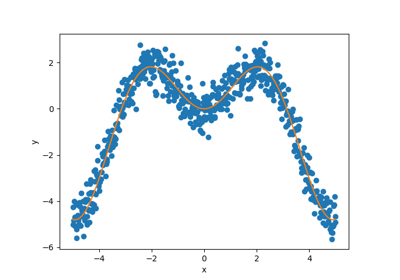
sphx_glr_examples_regression_2-advanced-analysis_plot_main-tutorial-regression.py
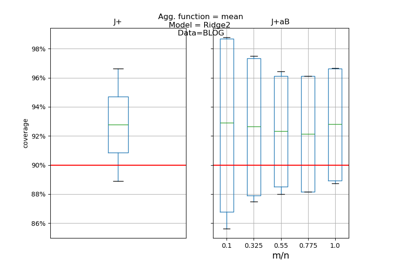
Predictive inference is free with the Jackknife+-after-Bootstrap, Kim et al. (2020)