mapie.regression.SplitConformalRegressor
- class mapie.regression.SplitConformalRegressor(estimator: RegressorMixin = LinearRegression(), confidence_level: float | Iterable[float] = 0.9, conformity_score: str | BaseRegressionScore = 'absolute', prefit: bool = True, n_jobs: int | None = None, verbose: int = 0)[source]
Computes prediction intervals using the split conformal regression technique:
The fit method (optional) fits the base regressor to the training data.
The conformalize method estimates the uncertainty of the base regressor by computing conformity scores on the conformalization set.
The predict_interval method predicts points and intervals.
- Parameters:
- estimatorRegressorMixin, default=LinearRegression()
The base regressor used to predict points.
- confidence_levelUnion[float, List[float]], default=0.9
The confidence level(s) for the prediction intervals, indicating the desired coverage probability of the prediction intervals. If a float is provided, it represents a single confidence level. If a list, multiple prediction intervals for each specified confidence level are returned.
- conformity_scoreUnion[str, BaseRegressionScore], default=”absolute”
The method used to compute conformity scores
Valid options:
“absolute”
“gamma”
“residual_normalized”
Any subclass of BaseRegressionScore
A custom score function inheriting from BaseRegressionScore may also be provided.
See [theoretical description (conformity scores)](../theory/conformity-scores.md).
- prefitbool, default=True
If True, the base regressor must be fitted, and the fit method must be skipped.
If False, the base regressor will be fitted during the fit method.
- n_jobsOptional[int], default=None
The number of jobs to run in parallel when applicable.
- verboseint, default=0
Controls the verbosity level. Higher values increase the output details.
Examples
>>> from mapie.regression import SplitConformalRegressor >>> from mapie.utils import train_conformalize_test_split >>> from sklearn.datasets import make_regression >>> from sklearn.linear_model import Ridge
>>> X, y = make_regression(n_samples=500, n_features=2, noise=1.0) >>> ( ... X_train, X_conformalize, X_test, ... y_train, y_conformalize, y_test ... ) = train_conformalize_test_split( ... X, y, train_size=0.6, conformalize_size=0.2, test_size=0.2, random_state=1 ... )
>>> mapie_regressor = SplitConformalRegressor( ... estimator=Ridge(), ... confidence_level=0.95, ... prefit=False, ... ).fit(X_train, y_train).conformalize(X_conformalize, y_conformalize)
>>> predicted_points, predicted_intervals = mapie_regressor.predict_interval(X_test)
- __init__(estimator: RegressorMixin = LinearRegression(), confidence_level: float | Iterable[float] = 0.9, conformity_score: str | BaseRegressionScore = 'absolute', prefit: bool = True, n_jobs: int | None = None, verbose: int = 0) None[source]
- conformalize(X_conformalize: ArrayLike, y_conformalize: ArrayLike, predict_params: dict | None = None) SplitConformalRegressor[source]
Estimates the uncertainty of the base regressor by computing conformity scores on the conformalization set.
- Parameters:
- X_conformalizeArrayLike
Features of the conformalization set.
- y_conformalizeArrayLike
Targets of the conformalization set.
- predict_paramsOptional[dict], default=None
Parameters to pass to the predict method of the base regressor. These parameters will also be used in the predict_interval and predict methods of this SplitConformalRegressor.
- Returns:
- Self
The conformalized SplitConformalRegressor instance.
- property conformity_scores: ndarray[tuple[Any, ...], dtype[_ScalarT]]
Returns the conformity scores computed by the conformalize method on the conformalization set.
- Returns:
- NDArray
Array of conformity scores, with shape (n_samples,).
- fit(X_train: ArrayLike, y_train: ArrayLike, fit_params: dict | None = None) SplitConformalRegressor[source]
Fits the base regressor to the training data.
- Parameters:
- X_trainArrayLike
Training data features.
- y_trainArrayLike
Training data targets.
- fit_paramsOptional[dict], default=None
Parameters to pass to the fit method of the base regressor.
- Returns:
- Self
The fitted SplitConformalRegressor instance.
- predict(X: ArrayLike) ndarray[tuple[Any, ...], dtype[_ScalarT]][source]
Predicts points.
- Parameters:
- XArrayLike
Features
- Returns:
- NDArray
Array of point predictions, with shape (n_samples,).
- predict_interval(X: ArrayLike, minimize_interval_width: bool = False, allow_infinite_bounds: bool = False) Tuple[ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]]][source]
Predicts points (using the base regressor) and intervals.
If several confidence levels were provided during initialisation, several intervals will be predicted for each sample. See the return signature.
- Parameters:
- XArrayLike
Features
- minimize_interval_widthbool, default=False
If True, attempts to minimize the intervals width.
- allow_infinite_boundsbool, default=False
If True, allows prediction intervals with infinite bounds.
- Returns:
- Tuple[NDArray, NDArray]
Two arrays:
Prediction points, of shape (n_samples,)
Prediction intervals, of shape (n_samples, 2, n_confidence_levels)
Examples using mapie.regression.SplitConformalRegressor
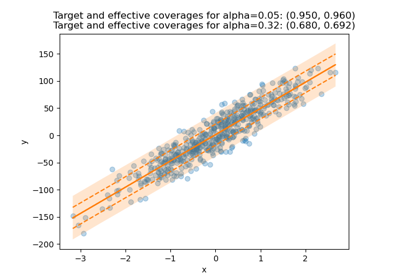
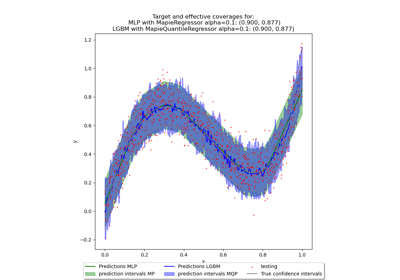
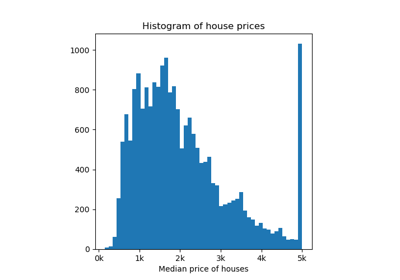


Online martingale exchangeability tests for a deployed regressor

sphx_glr_examples_mondrian_1-quickstart_plot_main-tutorial-mondrian-regression.py