mapie.utils.train_conformalize_test_split
- mapie.utils.train_conformalize_test_split(X: ndarray[tuple[Any, ...], dtype[_ScalarT]], y: ndarray[tuple[Any, ...], dtype[_ScalarT]], train_size: float | int, conformalize_size: float | int, test_size: float | int, random_state: int | None = None, shuffle: bool = True) Tuple[ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]]][source]
Split arrays or matrices into train, conformalization and test subsets.
Utility similar to sklearn.model_selection.train_test_split for splitting data into 3 sets.
We advise to give the major part of the data points to the train set and at least 200 data points to the conformalization set.
- Parameters:
- Xindexable with same type and length / shape[0] than “y”
Allowed inputs are lists, numpy arrays, scipy-sparse matrices or pandas dataframes.
- yindexable with same type and length / shape[0] than “X”
Allowed inputs are lists, numpy arrays, scipy-sparse matrices or pandas dataframes.
- train_sizefloat or int
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split. If int, represents the absolute number of train samples.
- conformalize_sizefloat or int
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the conformalize split. If int, represents the absolute number of conformalize samples.
- test_sizefloat or int
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the test split. If int, represents the absolute number of test samples.
- random_stateint, RandomState instance or None, default=None
Controls the shuffling applied to the data before applying the split. Pass an int for reproducible output across multiple function calls.
- shufflebool, default=True
Whether or not to shuffle the data before splitting.
- Returns:
- X_train, X_conformalize, X_test, y_train, y_conformalize, y_test
6 array-like splits of inputs. output types are the same as the input types.
Examples
>>> import numpy as np >>> from sklearn.datasets import make_regression >>> from mapie.utils import train_conformalize_test_split >>> X, y = np.arange(10).reshape((5, 2)), range(5) >>> X array([[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]]) >>> list(y) [0, 1, 2, 3, 4] >>> ( ... X_train, X_conformalize, X_test, ... y_train, y_conformalize, y_test ... ) = train_conformalize_test_split( ... X, y, train_size=0.6, conformalize_size=0.2, test_size=0.2, random_state=1 ... ) >>> X_train array([[8, 9], [0, 1], [6, 7]]) >>> X_conformalize array([[2, 3]]) >>> X_test array([[4, 5]]) >>> y_train [4, 0, 3] >>> y_conformalize [1] >>> y_test [2]
Examples using mapie.utils.train_conformalize_test_split
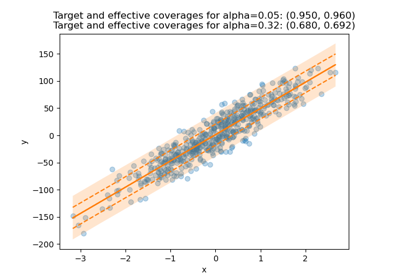
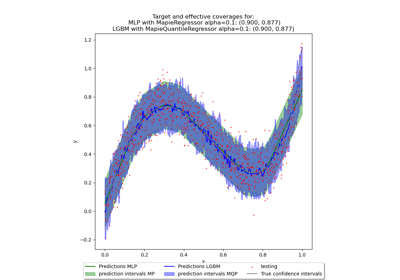

The symmetric correction parameter in conformalized quantile regression
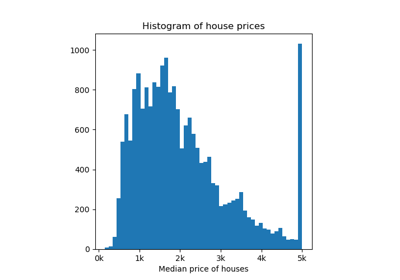

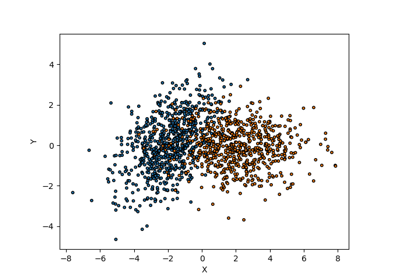
Set prediction example in the binary classification setting
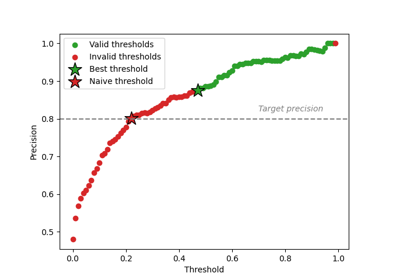
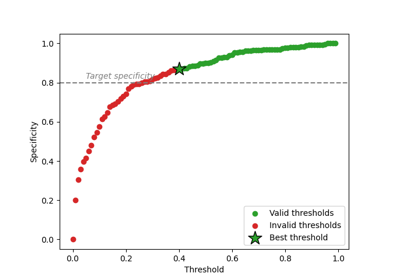
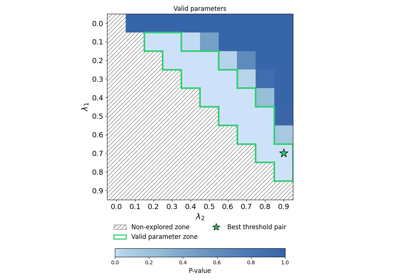
Control risk of a binary classifier with multiple prediction parameters
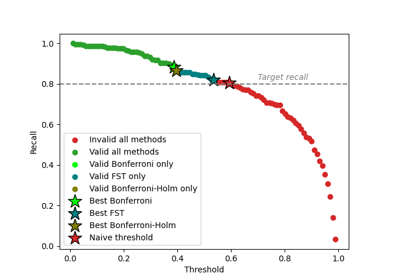
Comparing FWER methods for risk control in binary classification
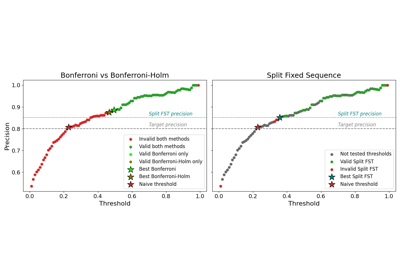
Split Fixed Sequence Testing for Precision Control under Multiple Testing
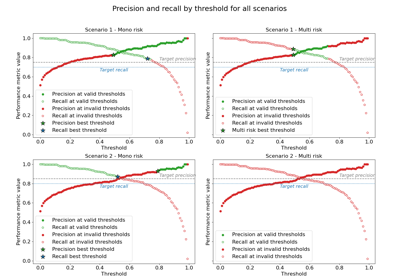
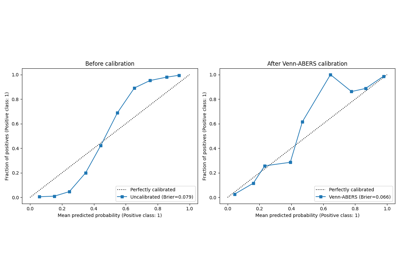
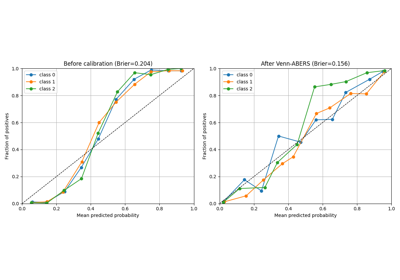
Calibrating multi-class classifier with Venn-ABERS

Online martingale exchangeability tests for a deployed regressor
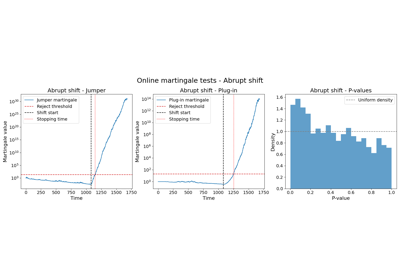
Online martingale exchangeability tests for a deployed classifier

sphx_glr_examples_mondrian_1-quickstart_plot_main-tutorial-mondrian-regression.py